لیست مطالب
در سال های اخیر، مدل های زبان بزرگ (LLMs) مانند GPT یا LLaMA به ابزار های قدرتمند و تحول آفرینی تبدیل شده اند. با این حال، استفاده از این مدل های عظیم برای Fine-Tune کردن (تنظیم دقیق) بر روی دیتای اختصاصی شما، چالش بزرگی است. نیاز به حافظه گرافیکی (VRAM) بسیار زیاد، این کار را برای اکثر کاربران، شرکت های کوچک غیر ممکن می سازد.
اینجاست که QLoRA وارد عمل می شود. QLoRA یک تکنیک انقلابی است که Fine-Tune کردن مدل های هوش مصنوعی غول پیکر را با استفاده از حافظه رم و VRAM بسیار کمتر، حتی بر روی یک لپ تاپ یا یک سرور مجازی کوچک، امکان پذیر می سازد.
QLoRA چیست و چگونه کار می کند؟
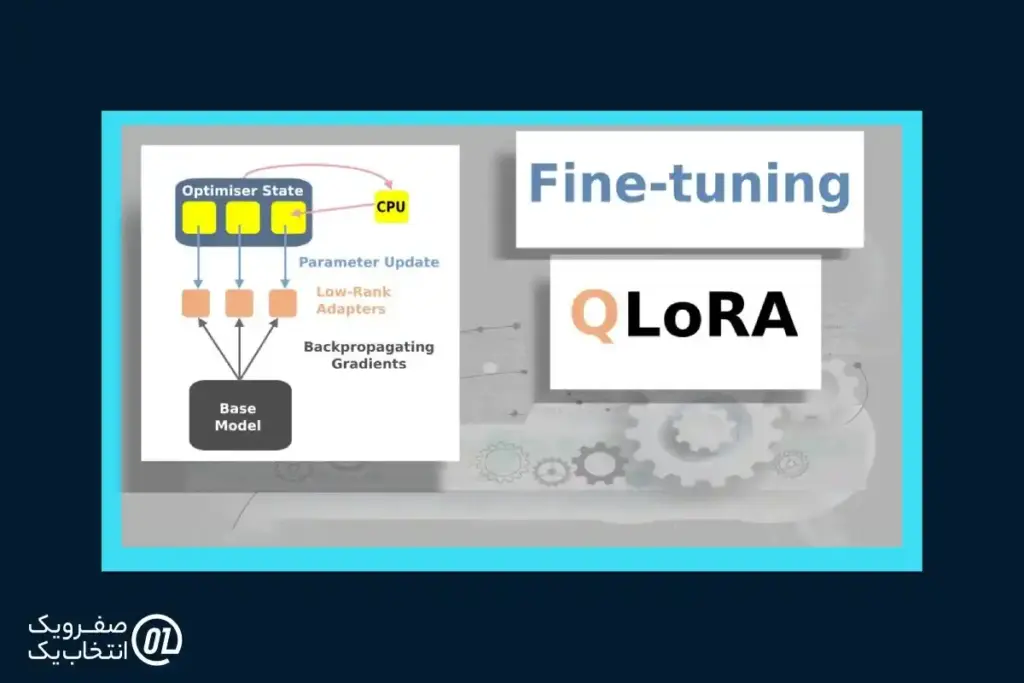
QLoRA (مخفف Quantized Low-Rank Adaptation) ترکیبی از دو فناوری کلیدی است: Quantization (کوانتیزاسیون) و LoRA (Low-Rank Adaptation).
1. کوانتیزاسیون (Quantization)
مدل های بزرگ هوش مصنوعی معمولا با دقت 16 یا 32 بیتی (مانند Float16) کار می کنند. این یعنی هر پارامتر مدل، 16 تا 32 بیت از حافظه را اشغال می کند. کوانتیزاسیون در QLoRA، این پارامتر ها را به صورت 4 بیتی ذخیره می کند. این کاهش حجم، باعث می شود که یک مدل با صدها میلیارد پارامتر، تنها به یک چهارم حافظه قبلی نیاز داشته باشد.
مزیت کلیدی: مدل اصلی را می توان با دقت بسیار پایین (4 بیت) ذخیره کرد و فقط در زمان نیاز به محاسبات، به دقت بالاتری تبدیل کرد، که این کار با کمترین هزینه سخت افزاری انجام می شود. صفرویک به زودی با سرور ابری و استفاده از آخرین فناوری های نوین ابری، این امکان را برای شما فراهم خواهد کرد.
2. LoRA (تنظیم رتبه پایین)
LoRA یک تکنیک Fine-Tune کردن است که به جای به روز رسانی تمامی پارامتر های مدل اصلی، لایه های رتبه پایین (Low-Rank) کوچکی را به مدل اضافه می کند. در زمان آموزش، فقط وزن های این لایه های کوچک تنظیم می شوند، در حالی که پارامتر های اصلی مدل ثابت باقی می مانند.
مزیت کلیدی: وزن های قابل آموزش تنها 0.01% از وزن های کل مدل را شامل می شوند. این یعنی به جای آموزش 70 میلیارد پارامتر، شما فقط چند میلیون پارامتر را آموزش می دهید!
QLoRA این دو تکنیک را ترکیب می کند: مدل اصلی 4 بیتی ذخیره می شود و Fine-Tune کردن فقط روی آداپتور های LoRA انجام می شود. این روش، بزرگ ترین چالش Fine-Tune کردن یعنی کمبود VRAM را حل می کند.
مراحل Fine-Tune کردن با QLoRA
برای شروع Fine-Tune کردن مدل های عظیم با QLoRA، کافی است چند مرحله ساده را دنبال کنید، که می توانید آنها را روی یک سرور مجازی با هزینه کم راه اندازی کنید:
- انتخاب مدل و دیتاست: یک LLM پایه (مثل LLaMA 2) و یک دیتاست کوچک و با کیفیت از داده های اختصاصی خودتان را انتخاب کنید.
- نصب کتابخانه ها: کتابخانه هایی مانند bitsandbytes (برای کوانتیزاسیون 4 بیتی) و PEFT (برای LoRA) را نصب کنید.
- پیکربندی QLoRA: تنظیمات کوانتیزاسیون 4 بیتی و پارامتر های LoRA (مانند رتبه LoRA یا آلفا) را تعریف کنید.
- شروع Fine-Tune: مدل را بارگذاری کرده و Fine-Tune کردن را شروع کنید. به دلیل استفاده بهینه از حافظه، این فرآیند بر روی سخت افزار شما قابل اجرا خواهد بود.
با استفاده از QLoRA، حتی مدل هایی مانند LLaMA 2 با 70 میلیارد پارامتر را می توان بر روی یک کارت گرافیک خانگی یا یک سرور کوچک با 10 تا 20 گیگابایت VRAM Fine-Tune کرد. این موضوع به شما امکان می دهد تا مدل های هوش مصنوعی را برای نیاز های خاص شرکت خودتان (مانند پاسخ گویی به سوال های مشتریان، تولید محتوای تخصصی، یا پردازش زبان فنی) سفارشی سازی کنید.
جمع بندی: دروازه ای به Fine-Tune کردن
QLoRA نه تنها یک پیشرفت فنی است، بلکه یک عامل دموکراتیک کننده در زمینه هوش مصنوعی محسوب می شود. این تکنیک، محدودیت های سخت افزاری گذشته را کنار زده و امکان Fine-Tune کردن مدل های عظیم را برای هر کسی که یک سرور اختصاصی یا حتی یک کامپیوتر معمولی دارد، فراهم می کند. با QLoRA، دیگر نیاز نیست برای استفاده از هوش مصنوعی، بزرگ ترین و گران ترین سرور ها را اجاره کنید. اکنون می توانید با کمترین هزینه و به آسانی، وب سایت یا مدل خود را راه اندازی کنید و دانش روز را در کسب و کارتان به کار بگیرید.
با صفرو یک به روز باشید!

آیا رویای استفاده از مدل های عظیم هوش مصنوعی برای کسب و کار خود را دارید اما نگران هزینه های سرور های گران قیمت هستید؟ با سرور های اختصاصی ایران و سرور های مجازی مقرون به صرفه صفرویک، دیگر نیازی به نگرانی نیست. همین امروز با مشاوران فنی صفرویک تماس بگیرید تا بهترین زیرساخت سخت افزاری را برای پیاده سازی تکنیک های پیشرفته ای مانند QLoRA و Fine-Tune کردن مدل های هوش مصنوعی شما، با کمترین هزینه و بالاترین پایداری، تامین کنیم. همین حالا تماس بگیرید و آینده هوش مصنوعی را در سرور خود آغاز کنید!