لیست مطالب
- پردازش زبان طبیعی (NLP) چیست؟
- مفاهیم مقدماتی NLP
- تاریخچه پردازش زبان طبیعی
- چرا NLP اهمیت دارد؟
- پردازش زبان طبیعی چگونه کار می کند؟
- الگوریتمهای پردازش زبان طبیعی
- بهترین الگوریتمهای NLP
- ابزارها و رویکردهای NLP
- مزایا و چالشهای پردازش زبان طبیعی (NLP)
- کاربردهای پردازش زبان طبیعی (NLP)
- انتظاراتمان از آینده پردازش زبان طبیعی چیست؟
- دنیای صفر و یک
- سوالات متداول
پردازش زبان طبیعی (NLP) چیست؟
پردازش زبان طبیعی (NLP) یکی از شاخههای مهم هوش مصنوعی است که به تعامل بین کامپیوترها و زبان انسانی می پردازد. هدف اصلی NLP این است که به ماشینها این امکان را بدهد که زبان طبیعی را درک، تحلیل و پردازش کنند. این فناوری به کمک الگوریتمها و مدلهای یادگیری ماشین، به کامپیوترها کمک میکند تا متن و گفتار انسانی را به صورت مؤثر تحلیل کنند و پاسخهای مناسبی ارائه دهند.
NLP شامل مجموعهای از تکنیکها و روشها است که به پردازش و تحلیل دادههای متنی و صوتی کمک میکند. از جمله این تکنیکها میتوان به توکن سازی، ریشه یابی، Lemmatization و مدل سازی موضوع اشاره کرد. با استفاده از این روشها، NLP میتواند به شناسایی الگوها، استخراج اطلاعات کلیدی و حتی تحلیل احساسات در متنها بپردازد.
با پیشرفتهای اخیر در یادگیری عمیق و شبکههای عصبی، NLP به یکی از ابزارهای کلیدی در بسیاری از کاربردها مانند ترجمه ماشینی، تحلیل احساسات و خدمات مشتری خودکار تبدیل شده است. این فناوری به ما کمک میکند تا ارتباطات بهتری با ماشینها برقرار کنیم و از دادههای متنی بهره برداری بیشتری داشته باشیم.
مفاهیم مقدماتی NLP
کیسه کلمات(Bag of Words)
کیسه کلمات یک روش ساده برای نمایش متن است که در آن متن به مجموعهای از کلمات تبدیل میشود و ترتیب آنها نادیده گرفته میشود. در این روش، هر کلمه به عنوان یک ویژگی در نظر گرفته میشود و تعداد دفعات تکرار آن در متن محاسبه میشود. این روش به تحلیل متن و استخراج ویژگیها کمک میکند، اما اطلاعات مربوط به ترتیب کلمات و ساختار جملات را از دست میدهد.
روش TFIDF
(TF-IDF (Term Frequency-Inverse Document Frequency یک تکنیک برای ارزیابی اهمیت یک کلمه در یک متن نسبت به مجموعهای از متون است. این روش با محاسبه فراوانی یک کلمه در یک سند (TF) و نسبت آن به تعداد اسنادی که آن کلمه در آنها وجود دارد (IDF)، به شناسایی کلمات کلیدی کمک میکند. TF-IDF به طور گسترده ای در جستجو و بازیابی اطلاعات استفاده میشود.
توکن سازی

توکن سازی فرآیندی است که در آن متن به واحدهای کوچکتر (توکنها) تقسیم میشود. این توکنها میتوانند کلمات، جملات یا عبارات باشند. توکن سازی اولین مرحله در پردازش زبان طبیعی است و به تحلیل و پردازش دادههای متنی کمک میکند.
ریشه یابی
ریشه یابی فرآیندی است که در آن کلمات به ریشه یا شکل پایه خود تبدیل میشوند. به عنوان مثال، کلمات "دویدن" و "دویدم" به ریشه "دو" تبدیل میشوند. این روش به کاهش تنوع کلمات و ساده سازی تحلیل متن کمک میکند، اما ممکن است دقت کلمات را کاهش دهد.
Lemmatization
Lemmatization مشابه ریشهیابی است، اما با استفاده از قوانین زبانشناسی، کلمات را به شکل پایه و صحیح خود تبدیل میکند. این روش به دقت بیشتری نسبت به ریشهیابی دست مییابد و به درک بهتر متن کمک میکند.
مدل سازی موضوع
مدل سازی موضوع فرآیندی است که در آن موضوعات اصلی یک متن شناسایی میشوند. این روش به تحلیل متون بزرگ و شناسایی الگوهای موضوعی کمک میکند و میتواند به درک بهتر محتوای متون کمک کند.
الگوریتم LDA
الگوریتم (LDA (Latent Dirichlet Allocation یکی از روشهای محبوب برای مدل سازی موضوع است. این الگوریتم به شناسایی موضوعات پنهان در یک مجموعه متنی کمک میکند و میتواند به تحلیل و دسته بندی متون بر اساس موضوعات مختلف کمک کند. LDA به طور گستردهای در تحلیل متون و استخراج اطلاعات استفاده میشود.
تاریخچه پردازش زبان طبیعی
تاریخچه پردازش زبان طبیعی (NLP) به دهه 1950 بازمیگردد، زمانی که دانشمندان برای اولین بار تلاش کردند تا ماشینها را قادر سازند زبان انسانی را درک کنند. یکی از نخستین پیشرفتها در این حوزه، آزمایش تورینگ (1950) بود که معیاری برای ارزیابی توانایی ماشینها در تقلید از انسان تعیین کرد.
در دهه 1960، پروژههایی مانند ماشین ترجمه جورج تاون آغاز شدند، اما به دلیل محدودیتهای فناوری، نتایج محدود و غیرقابل اعتماد بودند. در دهههای 1980 و 1990، با پیشرفت در یادگیری ماشین و الگوریتمهای آماری، NLP وارد مرحله جدیدی شد. روشهای آماری مانند مدلهای مارکوف پنهان (HMMs) برای تحلیل زبان معرفی شدند.

در دهه 2010، ظهور یادگیری عمیق و شبکههای عصبی تحول عظیمی در NLP ایجاد کرد. مدلهایی مانند BERT و GPT توانایی تحلیل و تولید زبان انسانی را به سطحی بی سابقه رساندند. اکنون NLP در بسیاری از کاربردها، از ترجمه ماشینی تا تحلیل احساسات، به یک ابزار کلیدی تبدیل شده است.
چرا NLP اهمیت دارد؟
پردازش زبان طبیعی (NLP) به دلیل توانایی اش در تسهیل تعامل بین انسان و ماشین، اهمیت زیادی دارد. این فناوری به کامپیوترها کمک میکند تا زبان انسانی را درک کرده و به آن پاسخ دهند، که این امر به بهبود تجربه کاربری و افزایش کارایی در بسیاری از زمینهها منجر میشود.
NLP در کاربردهایی مانند دستیاران صوتی، ترجمه ماشینی، و تحلیل احساسات به کار میرود و به سازمانها این امکان را میدهد که دادههای متنی را به صورت مؤثر تحلیل کنند. این فناوری به کسبوکارها کمک میکند تا ارتباطات بهتری با مشتریان برقرار کنند و خدمات خود را بهبود بخشند.
علاوه بر این، NLP به تحلیل دادههای بزرگ و استخراج اطلاعات ارزشمند از متون کمک میکند، که این امر در تصمیم گیریهای استراتژیک و تجزیه و تحلیل بازار بسیار مؤثر است. به طور کلی، NLP به عنوان یک ابزار کلیدی در دنیای دیجیتال امروز، نقش مهمی در تسهیل ارتباطات و بهینه سازی فرآیندها ایفا میکند.
پردازش زبان طبیعی چگونه کار می کند؟
پردازش زبان طبیعی (NLP) فرآیندی چند مرحلهای است که به کامپیوترها امکان میدهد تا زبان انسانی را درک، تحلیل و پردازش کنند. این فرآیند شامل دو مرحله اصلی است:
مرحله اول: پیش پردازش داده
در این مرحله، دادههای متنی به شکلی تبدیل میشوند که برای الگوریتمهای NLP قابل استفاده باشند. این شامل چندین تکنیک است: توکن سازی که متن را به واحدهای کوچکتر مانند کلمات یا جملات تقسیم میکند، و حذف توقف کلمات (Stop Words) که کلمات غیرضروری مانند "و"، "در" و "به" را حذف میکند. همچنین، ریشه یابی و Lemmatization به کاهش تنوع کلمات و تبدیل آنها به شکل پایه کمک میکند. این مراحل به کاهش حجم داده و افزایش دقت تحلیل کمک میکنند.
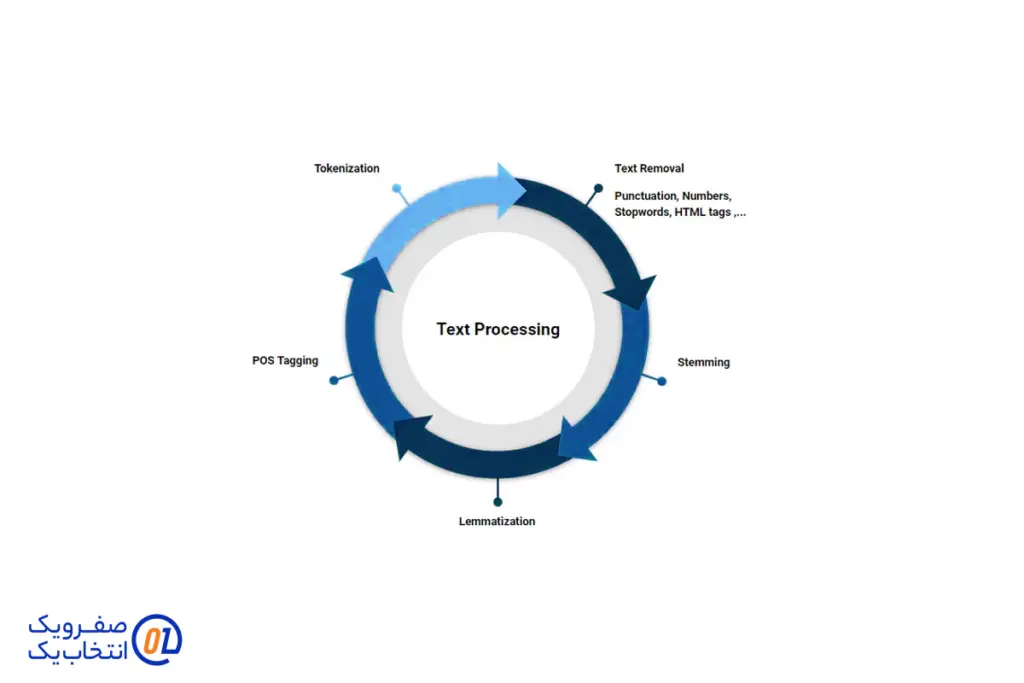
مرحله دوم: آموزش الگوریتم یا مدلهای پردازش زبان طبیعی
پس از پیش پردازش، دادههای آماده شده به مدلهای یادگیری ماشین یا یادگیری عمیق ارائه میشوند. این مدلها با استفاده از دادههای پردازش شده آموزش میبینند و میتوانند برای وظایفی مانند ترجمه ماشینی، تحلیل احساسات و خلاصه سازی متن به کار گرفته شوند. این مراحل به NLP این امکان را میدهند که به طور مؤثر با زبان انسانی تعامل داشته باشد و اطلاعات ارزشمندی استخراج کند.
الگوریتمهای پردازش زبان طبیعی
پردازش زبان طبیعی (NLP) به عنوان یکی از زیرشاخههای هوش مصنوعی، به تعامل بین کامپیوترها و زبان انسانی میپردازد. برای انجام این کار، الگوریتمهای مختلفی توسعه یافته اند که به سه دسته اصلی تقسیم میشوند: الگوریتمهای نمادین، الگوریتمهای آماری و الگوریتمهای ترکیبی. در ادامه به بررسی هر یک از این دستهها می پردازیم.
الگوریتمهای نمادین (Symbolic Algorithms)
الگوریتمهای نمادین بر اساس قوانین و منطق زبان شناسی عمل میکنند. این الگوریتمها به طور مستقیم به ساختار زبان و قواعد آن توجه دارند و معمولاً شامل سیستمهای مبتنی بر قاعده هستند. یکی از نمونههای معروف این الگوریتمها، سیستمهای مبتنی بر قاعده است که در آنها از مجموعهای از قوانین برای تحلیل و تولید زبان استفاده میشود. این الگوریتمها به دلیل دقت بالا در تحلیل زبانهای خاص و ساختارهای پیچیده، در کاربردهایی مانند ترجمه ماشینی و تحلیل متنهای تخصصی مورد استفاده قرار میگیرند.
با این حال، الگوریتمهای نمادین دارای محدودیتهایی نیز هستند. آنها معمولاً به دلیل نیاز به دانش عمیق زبانشناسی و قواعد زبان، زمانبر و پیچیده هستند. همچنین، این الگوریتمها در مواجهه با زبانهای غیررسمی یا محاورهای ممکن است دقت کمتری داشته باشند.
الگوریتمهای آماری (Statistical Algorithms)
الگوریتم های آماری بر اساس دادههای تجربی و تحلیل های آماری عمل می کنند. این الگوریتمها به جای استفاده از قواعد زبان شناسی، از دادههای بزرگ و الگوهای موجود در آنها برای تحلیل و پردازش زبان استفاده می کنند. یکی از معروف ترین الگوریتمهای آماری، مدلهای مارکوف پنهان (HMM) است که برای شناسایی توالیها و پیش بینی کلمات در متنها به کار می رود.
این الگوریتمها به دلیل تواناییشان در یادگیری از دادههای بزرگ و شناسایی الگوهای پیچیده، در کاربردهایی مانند تحلیل احساسات، شناسایی گفتار و ترجمه ماشینی بسیار مؤثر هستند. با این حال، الگوریتمهای آماری به دادههای باکیفیت و حجم بالا نیاز دارند و در صورت عدم وجود دادههای کافی، ممکن است دقت کمتری داشته باشند.
الگوریتمهای ترکیبی (Hybrid Algorithms)
الگوریتمهای ترکیبی، ترکیبی از الگوریتمهای نمادین و آماری هستند و سعی دارند از مزایای هر دو دسته بهرهبرداری کنند. این الگوریتمها معمولاً از قواعد زبانشناسی برای تحلیل ساختار زبان و از دادههای آماری برای یادگیری الگوها و ویژگیهای زبان استفاده میکنند. به عنوان مثال، مدلهای یادگیری عمیق که در آنها از شبکههای عصبی برای تحلیل دادههای متنی استفاده میشود، نمونهای از الگوریتمهای ترکیبی هستند.
این الگوریتمها به دلیل تواناییشان در یادگیری از دادههای بزرگ و همچنین درک ساختار زبان، در بسیاری از کاربردهای NLP مانند ترجمه ماشینی، تحلیل احساسات و خلاصهسازی متن بسیار مؤثر هستند. با این حال، پیادهسازی و آموزش این الگوریتمها ممکن است پیچیده و زمان بر باشد.
جمع بندی
در نهایت، انتخاب الگوریتم مناسب برای پردازش زبان طبیعی بستگی به نوع دادهها، هدف پروژه و نیازهای خاص آن دارد. الگوریتمهای نمادین برای تحلیلهای دقیق و تخصصی مناسب هستند، در حالی که الگوریتمهای آماری برای کار با دادههای بزرگ و شناسایی الگوها مؤثرترند. الگوریتمهای ترکیبی نیز به عنوان یک راهحل جامع، میتوانند از مزایای هر دو دسته بهره برداری کنند و به بهبود عملکرد سیستمهای NLP کمک کنند. با پیشرفتهای روزافزون در این حوزه، انتظار میرود که الگوریتمهای جدید و بهبود یافتهای نیز به زودی معرفی شوند که تواناییهای پردازش زبان طبیعی را به سطح جدیدی برسانند.
بهترین الگوریتمهای NLP
پردازش زبان طبیعی (NLP) به عنوان یک شاخه از هوش مصنوعی، ابزارها و الگوریتمهای متعددی را برای تحلیل و پردازش زبان انسانی ارائه میدهد. به بررسی بهترین الگوریتمهای NLP می پردازیم که شامل مدل سازی موضوع، خلاصه سازی متن، تحلیل احساسات، استخراج کلمه کلیدی، نمودارهای دانش، TF-IDF و ابر کلمات است.
مدل سازی موضوع (Topic Modeling)
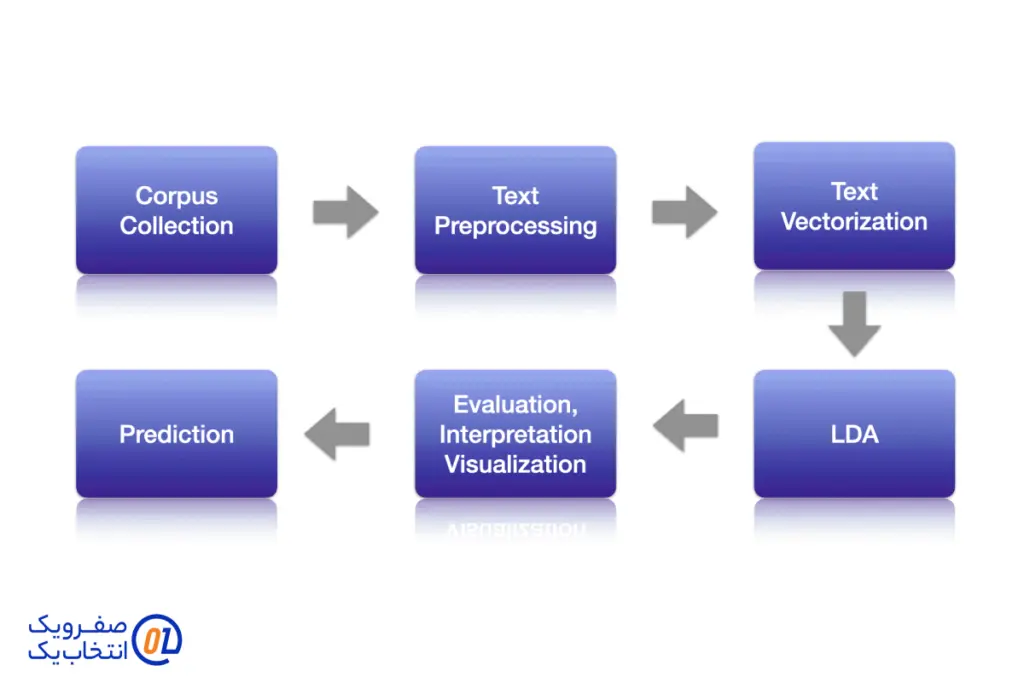
مدل سازی موضوع یک تکنیک در NLP است که به شناسایی موضوعات اصلی موجود در یک مجموعه متنی کمک میکند. این روش به ویژه در تحلیل متون بزرگ و شناسایی الگوهای موضوعی مفید است. دو الگوریتم معروف در این زمینه عبارتند از:
- (LDA (Latent Dirichlet Allocation: این الگوریتم یکی از روشهای پیشرفته برای مدل سازی موضوع است که به شناسایی موضوعات پنهان در متون کمک میکند. LDA فرض میکند که هر سند یک ترکیب از چندین موضوع است و هر موضوع نیز یک توزیع از کلمات دارد. این الگوریتم به طور گسترده در تحلیل متون، دسته بندی و بازیابی اطلاعات استفاده میشود.
- (NMF (Non-negative Matrix Factorization: این الگوریتم رویکردی دیگر برای مدل سازی موضوع است که با استفاده از ماتریسهای غیرمنفی، موضوعات را شناسایی میکند. NMF به ویژه در مواقعی که دادهها بزرگ و پیچیده هستند، کارایی بالایی دارد. این الگوریتم به تحلیل ساختار دادهها کمک میکند و میتواند به شناسایی موضوعات اصلی در متون کمک کند.
مدل سازی موضوع به محققان این امکان را میدهد که به سرعت محتوای متون بزرگ را بررسی کنند و الگوهای موجود در آنها را شناسایی کنند.
خلاصه سازی متن (Text Summarization)
خلاصه سازی متن فرآیندی است که هدف آن تولید یک خلاصه مختصر از متن اصلی است. این الگوریتم به ویژه در مواقعی که نیاز به بررسی سریع محتوای یک متن بزرگ وجود دارد، بسیار مفید است. خلاصه سازی متن به دو صورت انجام میشود:
- خلاصه سازی استخراجی: در این روش، جملات یا عبارات مهم از متن اصلی انتخاب میشوند و در خلاصه قرار میگیرند. الگوریتمهایی مانند TextRank و LexRank برای این منظور استفاده میشوند. این الگوریتمها به تحلیل متون و شناسایی جملات کلیدی کمک میکنند.
- خلاصه سازی انتزاعی: در این روش، الگوریتم به تولید جملات جدید برای خلاصه سازی متن می پردازد. این روش به یادگیری عمیق و شبکههای عصبی نیاز دارد و به دقت بالاتری نسبت به خلاصه سازی استخراجی دست مییابد. الگوریتمهایی مانند Seq2Seq و Transformers برای این منظور استفاده میشوند.
خلاصه سازی متن به کاربران این امکان را میدهد که در زمان کمتری به اطلاعات مورد نیاز دسترسی پیدا کنند و از حجم زیاد اطلاعات جلوگیری کنند.
تحلیل احساسات (Sentimental Analysis)
تحلیل احساسات یک تکنیک NLP است که به شناسایی و استخراج احساسات موجود در متن می پردازد. این الگوریتم به ویژه در تحلیل نظرات مشتریان، بررسی احساسات عمومی در رسانههای اجتماعی و ارزیابی بازخوردهای کاربران کاربرد دارد.
الگوریتمهای تحلیل احساسات معمولاً به دو دسته تقسیم میشوند:
- روشهای مبتنی بر قواعد: این روشها از مجموعهای از قواعد و واژههای کلیدی استفاده میکنند تا احساسات مثبت، منفی یا خنثی را شناسایی کنند. این رویکرد ساده است اما ممکن است در تحلیل متون پیچیده دقت کمتری داشته باشد.
- روشهای مبتنی بر یادگیری ماشین: این روشها از الگوریتمهای یادگیری ماشین برای تحلیل احساسات استفاده میکنند. الگوریتمهایی مانند SVM (Support Vector Machines)، Random Forest و شبکههای عصبی برای این منظور به کار می روند. این روشها به دلیل یادگیری از دادههای بزرگ و شناسایی الگوهای پیچیده، دقت بالاتری دارند.
تحلیل احساسات به کسب و کارها کمک میکند تا بازخورد مشتریان را بهتر درک کنند و استراتژیهای بهتری برای بهبود خدمات و محصولات خود توسعه دهند.
استخراج کلمه کلیدی (Keyword Extraction)
استخراج کلمه کلیدی به شناسایی و استخراج کلمات یا عبارات مهم از یک متن اشاره دارد. این فرآیند به کاربران کمک میکند تا به سرعت به اطلاعات کلیدی و مهم دسترسی پیدا کنند. استخراج کلمه کلیدی معمولاً در زمینههای جستجو، بهینه سازی موتور جستجو (SEO) و تحلیل محتوا کاربرد دارد.
روشهای مختلفی برای استخراج کلمات کلیدی وجود دارد که شامل:
- روشهای آماری: این روشها معمولاً از تکنیکهایی مانند TF-IDF (Term Frequency-Inverse Document Frequency) برای شناسایی کلمات کلیدی استفاده میکنند. TF-IDF به شناسایی کلمات مهم در یک متن نسبت به مجموعهای از متون کمک میکند.
- روشهای مبتنی بر یادگیری ماشین: این روشها از الگوریتمهای یادگیری ماشین برای تحلیل و استخراج کلمات کلیدی استفاده میکنند. الگوریتمهایی مانند LDA و TextRank به عنوان ابزارهایی برای استخراج کلمات کلیدی به کار میروند.
استخراج کلمه کلیدی به وبسایتها کمک میکند تا محتوای خود را بهینه سازی کنند و نتایج بهتری در جستجوها کسب کنند.
نمودارهای دانش (Knowledge Graphs)

نمودارهای دانش ابزارهایی هستند که به نمایش روابط و اطلاعات بین موجودیتهای مختلف کمک میکنند. این ابزارها به کاربر این امکان را میدهند که اطلاعات را به صورت بصری مشاهده کند و به درک بهتری از دادهها دست یابد. نمودارهای دانش معمولاً در موتورهای جستجو، سیستمهای توصیهگر و تحلیل دادهها کاربرد دارند.
نمودارهای دانش به کمک الگوریتمهای یادگیری ماشین و تکنیکهای NLP ایجاد میشوند. این نمودارها اطلاعات را به صورت گرافی نمایش میدهند که در آن موجودیتها به عنوان گرهها و روابط بین آنها به عنوان یالها نمایش داده میشوند.
به عنوان مثال، در یک نمودار دانش مرتبط با فیلمها، گرهها میتوانند شامل نام بازیگران، کارگردانان و فیلمها باشند و یالها روابط بین آنها را نشان میدهند. این نمودارها به کاربران کمک میکنند تا اطلاعات را به صورت منسجم و مرتبط مشاهده کنند.
TF-IDF
(TF-IDF (Term Frequency-Inverse Document Frequencyیک روش آماری برای اندازهگیری اهمیت یک کلمه در یک مجموعه از متون است. این روش به شناسایی کلمات کلیدی و مهم در متن کمک میکند و به عنوان ابزاری در جستجوها و بازیابی اطلاعات کاربرد دارد.
مفاهیم اصلی TF-IDF شامل:
- (TF (Term Frequency: تعداد دفعاتی که یک کلمه در یک سند خاص ظاهر میشود.
- (IDF (Inverse Document Frequency: معیاری که نشان میدهد یک کلمه چقدر در مجموعهای از اسناد نادر است. این معیار به کلمات عمومی و رایج وزن کمتری میدهد.
محاسبه TF-IDF به این صورت است:
(TF-IDF(t,d)=TF(t,d)×IDF(t
که در آن t کلمه، d سند و TF و IDF به ترتیب به توزیع فراوانی و فراوانی معکوس کلمه اشاره دارند.
این روش به ویژه در تحلیل متن و دستهبندی اطلاعات مورد استفاده قرار میگیرد و به کسبوکارها کمک میکند تا به سرعت به اطلاعات کلیدی دسترسی پیدا کنند.
ابر کلمات (Words Cloud)
ابر کلمات یا Word Cloud یک ابزار بصری است که به نمایش کلمات مهم و کلیدی در یک متن میپردازد. در ابر کلمات، اندازه هر کلمه نشاندهنده فراوانی آن در متن است؛ هر چه یک کلمه بیشتر تکرار شده باشد، بزرگتر و برجسته تر نمایش داده میشود.

ابر کلمات به عنوان یک ابزار تحلیلی و بصری، به کاربران کمک میکند تا به سرعت به درک بهتری از محتوای یک متن برسند. این ابزار به ویژه در تحلیل نظرات مشتریان، بررسی محتوای شبکههای اجتماعی و تجزیه و تحلیل متون علمی کاربرد دارد.
ایجاد ابر کلمات به سادگی با استفاده از ابزارهای مختلف نرمافزاری امکان پذیر است و میتواند به عنوان یک روش مؤثر برای ارائه نتایج تحلیل به صورت بصری و جذاب استفاده شود.
ابزارها و رویکردهای NLP
پردازش زبان طبیعی (NLP) به عنوان یک حوزه مهم در هوش مصنوعی، از ابزارها و رویکردهای مختلفی برای تحلیل و پردازش زبان انسانی بهره میبرد. در اینجا به دو ابزار و رویکرد کلیدی در NLP اشاره میکنیم: پایتون و the Natural Language Toolkit و یادگیری ماشین و یادگیری عمیق.
پایتون و (the Natural Language Toolkit (NLTK
پایتون به عنوان یکی از محبوب ترین زبانهای برنامه نویسی در حوزه یادگیری ماشین و NLP شناخته میشود. یکی از کتابخانههای برجسته پایتون، (NLTK) است. این کتابخانه مجموعهای از ابزارها و منابع برای پردازش زبان طبیعی ارائه میدهد و به محققان و توسعه دهندگان این امکان را میدهد که به راحتی وظایف مختلف NLP را انجام دهند. NLTK شامل توکن سازی، حذف توقفکلمات، تحلیل نحوی، و مدلسازی موضوع است و به کاربران این قابلیت را میدهد که به سرعت و به سادگی پروژههای NLP خود را پیاده سازی کنند.
یادگیری ماشین و یادگیری عمیق
یادگیری ماشین و یادگیری عمیق دو رویکرد مهم در توسعه الگوریتمهای NLP هستند. یادگیری ماشین به ما این امکان را میدهد که از دادههای آموزشی برای شناسایی الگوها و پیشبینی نتایج استفاده کنیم. الگوریتمهایی مانند Support Vector Machines و Random Forest در تحلیل احساسات و دسته بندی متن بسیار مؤثر هستند.
از سوی دیگر، یادگیری عمیق با استفاده از شبکههای عصبی پیچیده، به ویژه در پردازش زبان طبیعی تحول بزرگی ایجاد کرده است. مدلهایی مانند Transformers و BERT توانایی درک و تولید زبان انسانی را به سطوح جدیدی ارتقا دادهاند. این رویکردها به تحلیل متون پیچیده و تولید متنهای طبیعی کمک میکنند و به طور کلی دقت و کارایی سیستمهای NLP را افزایش میدهند.
مزایا و چالشهای پردازش زبان طبیعی (NLP)

پردازش زبان طبیعی (NLP) به عنوان یکی از زیرشاخههای هوش مصنوعی، نقش مهمی در بهبود تعامل بین انسان و کامپیوتر ایفا میکند. این فناوری به کامپیوترها امکان میدهد تا زبان انسانی را درک کرده، تحلیل کنند و به آن پاسخ دهند. اگرچه NLP مزایای بسیاری دارد، اما با چالشهایی نیز روبرو است که حل آنها نیازمند تلاشهای بیشتر در حوزهی تکنولوژی و تحقیق است. در ادامه به بررسی مزایا و چالشهای پردازش زبان طبیعی می پردازیم.
مزایای پردازش زبان طبیعی
1. افزایش کارایی
یکی از بزرگ ترین مزایای NLP، افزایش کارایی در انجام وظایف مرتبط با متن و زبان است. با استفاده از الگوریتمهای NLP، وظایفی که به صورت دستی زمانبر هستند، مانند تحلیل مقالات، بررسی نظرات کاربران یا شناسایی اطلاعات کلیدی از میان دادههای متنی، به صورت خودکار انجام میشوند. به عنوان مثال:
- اتوماسیون فرآیندها: NLP میتواند به طور خودکار ایمیلها را دستهبندی کند، پرسشهای متداول را پاسخ دهد یا اطلاعات مهم را از مکالمات استخراج کند.
- سرعت بالا: مدلهای NLP میتوانند در عرض چند ثانیه اطلاعات را پردازش کنند، در حالی که انجام این کار توسط انسان ممکن است ساعتها طول بکشد.
این افزایش کارایی به سازمانها کمک میکند تا بهرهوری را افزایش دهند و در زمان و هزینههای خود صرفه جویی کنند.
2. بهبود ارتباطات
NLP در بهبود ارتباطات بین انسان و ماشین نقش کلیدی دارد. ابزارهایی مانند دستیارهای صوتی (مانند Siri، Alexa و Google Assistant) و چتباتها به کاربران این امکان را میدهند که با ماشینها به زبان طبیعی خود تعامل کنند. بهبود ارتباطات از طریق NLP شامل موارد زیر است:
- ترجمه ماشینی: ابزارهایی مانند Google Translate با استفاده از NLP به کاربران کمک میکنند تا به راحتی با افراد از زبانهای مختلف ارتباط برقرار کنند.
- دستیارهای صوتی: این دستیارها میتوانند دستورات کاربر را درک کرده و پاسخهای مفیدی ارائه دهند، که این امر تجربه کاربری را بهبود میبخشد.
این قابلیتها باعث میشود که افراد بتوانند به راحتی از تکنولوژی استفاده کرده و با دستگاههای دیجیتال تعامل راحت تری داشته باشند.
3. دقت بهتر
یکی دیگر از مزایای NLP، دقت بالا در تحلیل دادههای متنی است. الگوریتمهای پیشرفته پردازش زبان طبیعی توانایی تحلیل دقیق متون پیچیده و استخراج اطلاعات مرتبط را دارند. برای مثال:

- در تحلیل احساسات، NLP میتواند به دقت احساسات مثبت، منفی یا خنثی را از نظرات کاربران شناسایی کند.
- در مدلسازی موضوع، NLP میتواند موضوعات پنهان موجود در مجموعههای بزرگ متنی را شناسایی کند.
این دقت بالا به سازمانها و تحلیلگران کمک میکند تا تصمیمات آگاهانهتری بر اساس دادههای متنی بگیرند.
4. بهبود تجربه مشتری
NLP به طور چشمگیری در بهبود تجربه مشتری نقش دارد. بسیاری از شرکتها از چت باتها و سیستمهای پاسخگوی هوشمند استفاده میکنند که مبتنی بر NLP هستند. این سیستمها میتوانند:
- به سرعت به سوالات مشتریان پاسخ دهند.
- درخواستهای مشتریان را تحلیل کرده و راه حلهای مناسب ارائه کنند.
- رضایت مشتری را با ارائه خدمات سریعتر و شخصی تر افزایش دهند.
بهبود تجربه مشتری به شرکتها کمک میکند تا ارتباطات خود با مشتریان را بهبود بخشیده و وفاداری آنها را افزایش دهند.
5. تجزیه و تحلیل روشنگرانه
یکی از دیگر مزایای NLP، تجزیه و تحلیل روشنگرانه دادههای متنی است. این فناوری میتواند از میان حجم انبوهی از دادههای متنی، الگوها و اطلاعات ارزشمند را استخراج کند. به عنوان مثال:
در تحلیل دادههای شبکههای اجتماعی، NLP میتواند نظرات و احساسات کاربران را نسبت به یک برند یا محصول شناسایی کند.
در تحقیقهای علمی، الگوریتمهای NLP میتوانند مقالات علمی را تحلیل کرده و روندهای تحقیقاتی را شناسایی کنند.
این تجزیه و تحلیلها به سازمانها کمک میکند تا تصمیمات استراتژیکتری اتخاذ کنند و در بازار رقابتی موفقتر عمل کنند.
چالشهای پردازش زبان طبیعی
1. پیچیدگی زبان انسانی
یکی از بزرگ ترین چالشهای NLP، پیچیدگی زبان انسانی است. زبانها دارای ساختارهای گرامری پیچیده، اصطلاحات محاورهای، جملات چند معنا و تفاوتهای فرهنگی هستند. به عنوان مثال:
- ابهام معنایی: برخی از کلمات یا جملات ممکن است بسته به زمینه، معانی متفاوتی داشته باشند. این مسئله میتواند درک دقیق متن را برای مدلهای NLP دشوار کند.
- زبانهای مختلف: الگوریتمهای NLP معمولاً برای زبانهای رایج مانند انگلیسی طراحی میشوند و ممکن است در زبانهای دیگر مانند فارسی یا زبانهای محلی دقت کمتری داشته باشند.
برای حل این چالش، نیاز به توسعه مدلهای چندزبانه و درک بهتر از تفاوتهای زبانی و فرهنگی وجود دارد.
2. نیاز به دادههای باکیفیت و بزرگ

مدلهای NLP برای آموزش به حجم زیادی از دادههای با کیفیت نیاز دارند. این چالش به دلایل زیر مهم است:
- عدم دسترسی به دادههای مناسب: در بسیاری از مواقع، دادههای کافی برای زبانهای خاص یا حوزههای تخصصی وجود ندارد.
- هزینه بالا: جمع آوری، پردازش و برچسب گذاری دادهها فرآیندی پرهزینه و زمان بر است.
بدون دادههای باکیفیت، مدلهای NLP ممکن است عملکرد ضعیفی داشته باشند و نتایج نادرستی تولید کنند.
3. محدودیت در درک متنهای پیچیده
اگرچه الگوریتمهای NLP در سالهای اخیر پیشرفتهای زیادی داشتهاند، اما همچنان در پردازش متنهای پیچیده با چالش روبرو هستند. برخی از این محدودیتها شامل:
- درک زمینه: مدلهای NLP ممکن است نتوانند به درستی زمینه یا هدف یک متن را درک کنند.
- پردازش طنز و کنایه: تشخیص طنز، کنایه یا زبان غیرمستقیم برای مدلهای NLP دشوار است.
- متنهای نامنظم: متون محاورهای یا دارای غلطهای املایی و گرامری ممکن است به سختی توسط مدلها پردازش شوند.
کاربردهای پردازش زبان طبیعی (NLP)
پردازش زبان طبیعی (NLP) به عنوان یکی از شاخههای برجسته هوش مصنوعی در بسیاری از حوزهها کاربرد دارد. این فناوری امکان تعامل مؤثر بین انسان و ماشین را فراهم می کند و نقش مهمی در تحلیل و پردازش زبان انسانی ایفا میکند. در این مقاله به بررسی کاربردهای پردازش زبان طبیعی در حوزههای مختلف می پردازیم.
فیلترهای هرزنامه (Spam Filters)
یکی از ساده ترین و پراستفادهترین کاربردهای NLP، فیلتر کردن ایمیلهای هرزنامه است. این سیستمها از الگوریتمهای NLP برای شناسایی و دستهبندی پیامهای ناخواسته استفاده میکنند.
- چگونه کار میکند؟ با تحلیل محتوای ایمیل، کلمات کلیدی مرتبط با هرزنامه (مانند "رایگان"، "جایزه" یا "پیشنهاد ویژه") شناسایی میشوند.
- الگوریتمها: مدلهای یادگیری ماشین مانند Naive Bayes و SVM به طور گسترده در فیلترهای هرزنامه استفاده میشوند.
این کاربرد باعث میشود کاربران تنها ایمیلهای مرتبط و مهم را مشاهده کنند و از حجم زیاد پیامهای ناخواسته جلوگیری شود.
معاملات الگوریتمی (Algorithmic Trading)
در بازارهای مالی، NLP نقش کلیدی در معاملات الگوریتمی ایفا میکند. این فناوری به تحلیل اخبار، گزارشها و دادههای مالی کمک میکند تا تصمیمات معاملاتی به صورت خودکار گرفته شوند.
- چگونه کار میکند؟ NLP دادههای متنی (مانند اخبار اقتصادی یا توییتهای مرتبط با بازار) را پردازش کرده و تأثیر آنها بر بازار را پیشبینی میکند.
- مزایا: این سیستمها در کاهش زمان تصمیم گیری و افزایش دقت در معاملات مؤثر هستند.
به کمک NLP، سرمایه گذاران میتوانند به سرعت واکنش نشان دهند و از تغییرات بازار بهرهبرداری کنند.
پاسخ گویی به سوالات (Questions Answering)
سیستم های پاسخ گویی به سوالات یکی از پرکاربردترین ویژگیهای NLP هستند که به کاربران کمک میکنند تا پاسخ سوالات خود را به صورت دقیق و سریع دریافت کنند.
- چگونه کار میکند؟ این سیستمها متنهای موجود را جستجو کرده و پاسخ مرتبط را استخراج میکنند. مدلهایی مانند BERT و GPT در این زمینه پیشرو هستند.
- کاربردها: این فناوری در موتورهای جستجو، چتباتها و دستیارهای صوتی استفاده میشود.
این سیستمها تجربه کاربری را به طور چشمگیری بهبود میبخشند و اطلاعات را به صورت دقیق تر ارائه میدهند.
تصحیح خطای گرامری (Grammatical Error Correction)
NLP نقش مهمی در تصحیح خطاهای گرامری و املایی دارد. ابزارهایی مانند Grammarly و Microsoft Word از این فناوری برای شناسایی و اصلاح خطاهای متنی استفاده میکنند.
- چگونه کار میکند؟ با استفاده از مدلهای یادگیری ماشین، خطاهای گرامری و املایی در متن شناسایی و پیشنهاداتی برای اصلاح ارائه میشود.
- مزایا: این سیستمها به نویسندگان کمک میکنند تا متون صحیحتری تولید کنند و کیفیت محتوای خود را بهبود بخشند.
این ابزارها به ویژه در محیطهای حرفهای و آموزشی بسیار مفید هستند.
بهینه سازی موتور جستجو (SEO)
NLP در بهبود استراتژیهای بهینهسازی موتور جستجو (SEO) نقش دارد. این فناوری به تحلیل محتوا و شناسایی کلمات کلیدی مرتبط کمک می کند.
- چگونه کار میکند؟ NLP کلمات کلیدی را از محتوا استخراج کرده و پیشنهاداتی برای بهبود رتبه در نتایج جستجو ارائه میدهد.
- مزایا: این ابزارها به وبسایتها کمک میکنند تا ترافیک بیشتری دریافت کرده و کاربران هدفمندتری را جذب کنند.
NLP باعث میشود محتوای وبسایتها به طور موثرتری با الگوریتمهای موتورهای جستجو همخوانی داشته باشد.

خدمات مشتری خودکار (Automated Customer Service)
چت باتها و سیستم های پاسخ گویی خودکار یکی از مهمترین کاربردهای NLP در خدمات مشتریان هستند.
- چگونه کار میکنند؟ این سیستمها از NLP برای درک سوالات مشتریان و ارائه پاسخهای مناسب استفاده میکنند.
- مزایا: خدمات سریعتر، کاهش هزینهها و بهبود تجربه مشتری.
این فناوری به شرکتها کمک میکند تا به طور24 ساعته به مشتریان خود خدمات ارائه دهند.
تجزیه و تحلیل احساسات (Sentiment Analysis)
تحلیل احساسات یکی از پرکاربردترین تکنیکهای NLP است که به شناسایی احساسات مثبت، منفی یا خنثی از متن میپردازد.
- چگونه کار میکند؟ از مدلهای یادگیری ماشین برای تحلیل متون (مانند نظرات کاربران یا پستهای شبکههای اجتماعی) استفاده میشود.
- کاربردها: بررسی بازخورد مشتریان، تحلیل بازار و مدیریت برند.
این فناوری به شرکتها کمک میکند تا دیدگاه مشتریان خود را بهتر درک کنند.
طبقه بندی متن (Text Classification)
یکی دیگر از کاربردهای NLP، طبقه بندی متون است. این فناوری متنها را بر اساس موضوع یا دسته بندی خاصی مرتب میکند.
- چگونه کار میکند؟ با استفاده از الگوریتمهای یادگیری ماشین، متنها به دستههای مختلف (مانند اخبار، نظرات مثبت یا منفی) تقسیم میشوند.
- کاربردها: دستهبندی ایمیلها، تحلیل اخبار و سازماندهی دادهها.
این فرآیند به مدیریت بهتر اطلاعات و استخراج دادههای مفید کمک میکند.
سیستمهای تشخیص صدا (Voice Recognition Systems)
سیستمهای تشخیص صدا یکی از برجستهترین کاربردهای NLP هستند که به ماشینها امکان میدهند صدای انسان را درک کنند.
- چگونه کار میکنند؟ این سیستمها گفتار را به متن تبدیل کرده و سپس با استفاده از NLP متن را پردازش میکنند.
- کاربردها: دستیارهای صوتی، سیستمهای تماس خودکار و ابزارهای ترجمه.
این فناوری تجربه کاربری را در دستگاههای هوشمند بهبود میبخشد.
ترجمه ماشینی (Machine Translation)
ترجمه ماشینی یکی از معروف ترین کاربردهای NLP است که به ترجمه متن از یک زبان به زبان دیگر میپردازد.
- چگونه کار میکند؟ مدلهایی مانند Google Translate از NLP برای تحلیل ساختار زبان و ترجمه آن استفاده میکنند.
- مزایا: ترجمه سریعتر و دسترسی آسان به اطلاعات در زبانهای مختلف.
این فناوری به ارتباطات جهانی کمک شایانی کرده است.
تعامل انسان-رایانه (Human-Computer Interaction)

NLP نقش مهمی در بهبود تعامل بین انسان و رایانه دارد. این فناوری به ماشینها امکان میدهد تا زبان طبیعی انسان را درک کرده و پاسخ دهند.
- کاربردها: دستیارهای صوتی، چتباتها و سیستمهای پاسخ گویی هوشمند.
- مزایا: تجربه کاربری بهتر و ساده تر.
این تعامل باعث میشود کاربران بتوانند به راحتی با دستگاههای هوشمند کار کنند.
کاربردهای NLP در سایر حوزهها
پردازش زبان طبیعی در پزشکی
NLP در پزشکی نقش مهمی در تحلیل دادههای پزشکی، تشخیص بیماریها و استخراج اطلاعات از گزارشهای پزشکی ایفا میکند. این فناوری به پزشکان کمک میکند تا به سرعت به دادههای مرتبط دسترسی پیدا کرده و تصمیمات بهتری بگیرند.
پردازش زبان طبیعی در سیستمهای توصیه گر
سیستمهای توصیهگر مبتنی بر NLP به کاربران پیشنهاداتی ارائه میدهند که با علایق آنها همخوانی دارد. این فناوری در پلتفرمهایی مانند Amazon و Netflix استفاده میشود.رفع این محدودیتها نیازمند توسعه مدلهای پیشرفتهتر و بهبود تکنیکهای NLP است.
انتظاراتمان از آینده پردازش زبان طبیعی چیست؟
آینده پردازش زبان طبیعی (NLP) بهبود دقت و درک زبان انسانی را به همراه خواهد داشت. انتظار میرود سیستمهای NLP بهطور مؤثرتری با زبانهای محاورهای و فرهنگی تعامل کنند و قابلیتهای چندزبانه را افزایش دهند. همچنین، توسعه سیستمهای شخصیتر که بتوانند احساسات و نیت کاربر را تحلیل کنند، از اهداف اصلی است.
ادغام NLP با هوش مصنوعی عمومی میتواند تعامل انسان و ماشین را به سطح جدیدی برساند. همچنین، کاربردهای گستردهتری در حوزههای پزشکی، آموزش و تجارت پیشبینی میشود. در نهایت، تلاش برای کاهش سوگیریهای الگوریتمی و افزایش شفافیت مدلها نیز از مهم ترین اهداف آینده این فناوری خواهد بود.
دنیای صفر و یک
شرکت صفر و یک، به عنوان یکی از برترین کارآفرینان در زمینه ارائه خدمات اینترنت، میتواند با توجه به نیازهای مختلف مشتریان، خدمات متنوعی ارائه دهد.
برای اطلاعات بیشتر و دریافت خدمات ما، لطفاً با ما تماس بگیرید.
سوالات متداول
NLU و NLG در پردازش زبان طبیعی چیست؟
NLU (Natural Language Understanding)به درک زبان انسانی توسط ماشینها اشاره دارد، در حالی که NLG (Natural Language Generation) به تولید متن طبیعی از دادهها میپردازد.
بهترین زبان برنامه نویسی برای NLP چیست؟
پایتون به عنوان بهترین زبان برنامهنویسی برای NLP شناخته میشود، زیرا دارای کتابخانههای متعددی مانند NLTK و SpaCy است که توسعه را تسهیل میکند.
پیاده سازی NLP چگونه است؟
پیادهسازی NLP شامل مراحل پیشپردازش داده، انتخاب الگوریتم، آموزش مدل و ارزیابی عملکرد آن است. این مراحل به تحلیل و پردازش متن کمک میکنند.
فریمورکهای مشهور NLP چیست؟
فریمورکهای مشهور NLP شامل NLTK، SpaCy، Hugging Face Transformers و Gensim هستند که ابزارهای قدرتمندی برای پردازش زبان طبیعی ارائه میدهند.
فرق چت جیپیتی و ان ال پی چیست؟
چت جیپیتی یک مدل خاص از NLP است که برای تولید متن و پاسخ به سوالات طراحی شده است، در حالی که NLP به طور کلی به تمام تکنیکها و الگوریتمهای مرتبط با پردازش زبان انسانی اشاره دارد.