لیست مطالب
پس از مدتها انتظار، شرکت xAI سرانجام سومین نسخه از مدل Grok را منتشر کرد. گفته میشود که این مدل، هوشمندترین مدل زبانی (LLM) در جهان است و اولین مدلی است که در آزمون Chatbot Arena امتیازی بالاتر از 1400 کسب کرده است.
اما آیا این مدل جدید واقعاً بهترین مدل موجود (SOTA) است؟ ظاهراً بله.
اما عملکرد آن در مقایسه با مدل محبوب DeepSeek R1 چگونه است؟ Grok 3 روی یک خوشه عظیم 100 هزار پردازنده گرافیکی H100 آموزش دیده، که در مقایسه با DeepSeek R1، یک برتری ناعادلانه محسوب میشود. با این حال، از دیدگاه یک کاربر عادی، میخواستم ببینم که آیا این مدل به اندازهای که تبلیغ میشود، واقعاً خوب است یا نه. بنابراین، هر دو مدل را با مجموعهای از مسائل استدلالی، چالشهای ریاضی، وظایف برنامه نویسی و درخواستهای نویسندگی خلاقانه آزمایش کردم.
بیایید ببینیم چه نتیجهای گرفتیم.
خلاصه نتایج (TL;DR)
اگر میخواهید مستقیماً به نتیجه برسید، این خلاصهای از مقایسه بین این مدلها است:
- استدلال و ریاضی: مدلهای DeepSeek R1 و Grok 3 عملکردی تقریباً مشابه در حل مسائل استدلالی دارند.
- برنامه نویسی: Grok 3 به طور قابل توجهی بهتر از DeepSeek R1 عمل میکند و کدهای باکیفیتتری تولید میکند.
- نویسندگی خلاقانه: هر دو مدل در این زمینه خوب عمل میکنند، اما من شخصاً Grok 3 را ترجیح میدهم.
مروری بر مدل Grok 3
Grok 3 جدیدترین مدل زبان از شرکت xAI است که 10 برابر قدرت پردازشی بیشتری نسبت به نسخههای قبلی دارد. این مدل دارای قابلیتهایی مانند DeepSearch برای استدلال مرحله به مرحله و Big Brain Mode برای مدیریت وظایف پیچیده است.
این مدل را میتوانید به صورت رایگان از طریق حساب X/Twitter خود امتحان کنید، البته فعلاً با محدودیتهای سختگیرانه.
طبق بنچمارکهای رسمی که تیم xAI در رویداد رونمایی منتشر کرده، Grok 3 یک مدل انقلابی محسوب میشود و تقریباً در تمامی معیارها از رقبا پیشی گرفته است.
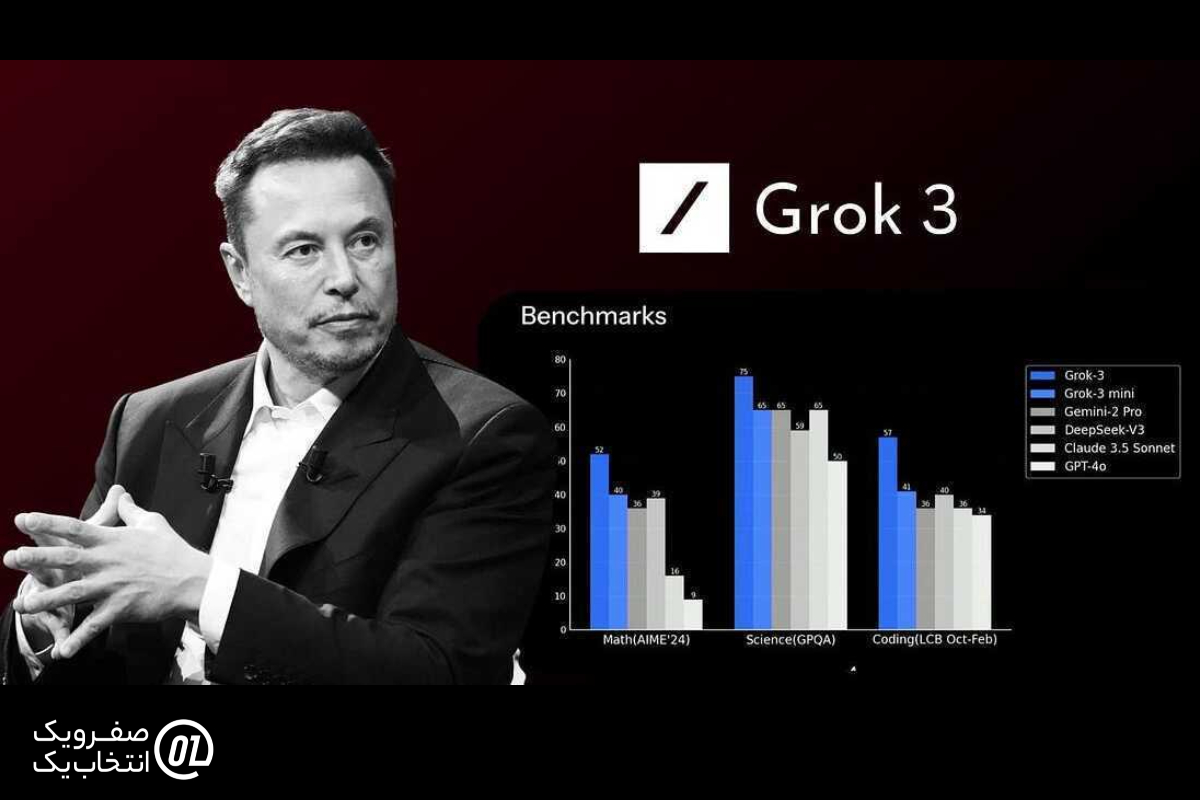
مقایسه DeepSeek R1 و Grok 3
برای بررسی عملکرد این دو مدل، از Chatbot Arena استفاده کردهام؛ این پلتفرم تنها منبع معتبر و مستقل است که امکان آزمایش نسخه اولیه Grok 3 را فراهم میکند.
آزمونهای استدلالی
در این بخش، تواناییهای استدلالی هر دو مدل را بررسی خواهیم کرد.
۱. رولت روسی
بیایید با یک سؤال جالب شروع کنیم:
پرسش:
شما در حال بازی رولت روسی با یک هفتتیر ششتیر هستید. حریف شما پنج گلوله درون خشاب قرار میدهد، آن را میچرخاند و ماشه را روی خودش میچکاند، اما گلولهای شلیک نمیشود. او به شما این امکان را میدهد که انتخاب کنید آیا قبل از شلیک به شما، خشاب را دوباره بچرخاند یا نه. آیا باید اجازه دهید خشاب دوباره چرخانده شود؟
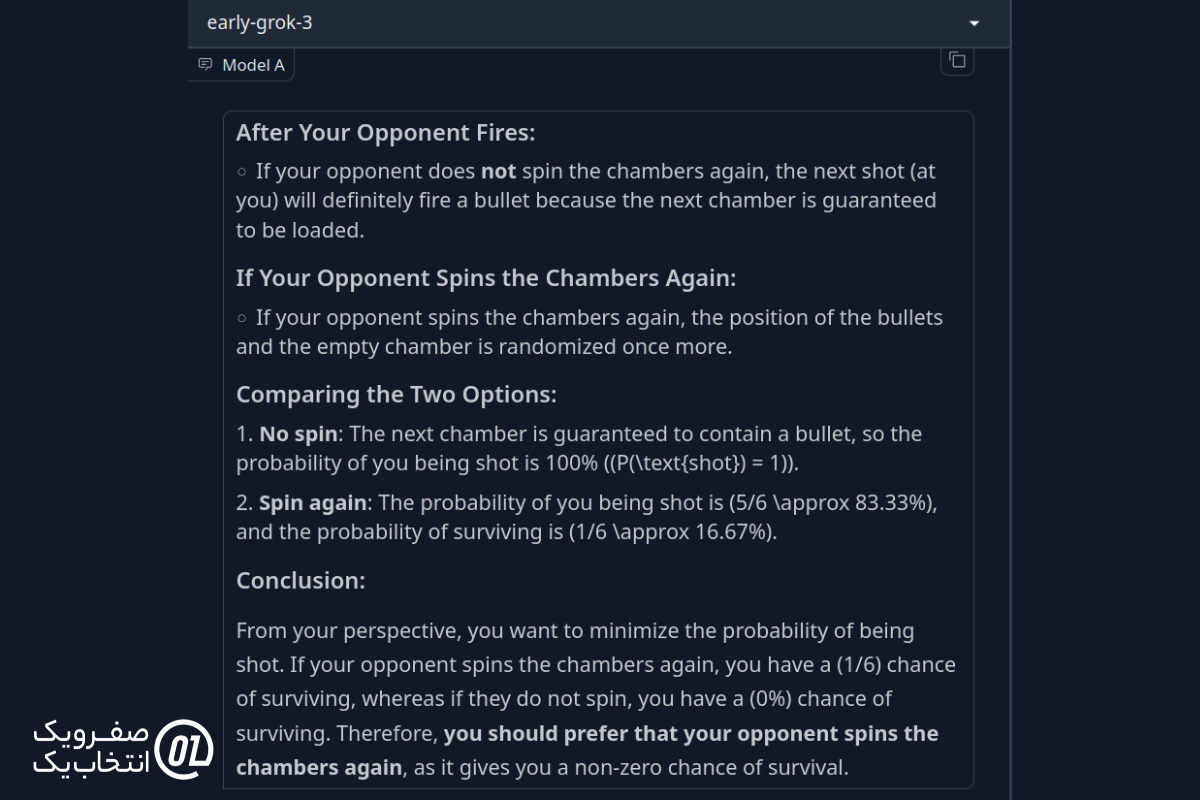
پاسخ Grok 3:
پاسخ از DeepSeek R1:
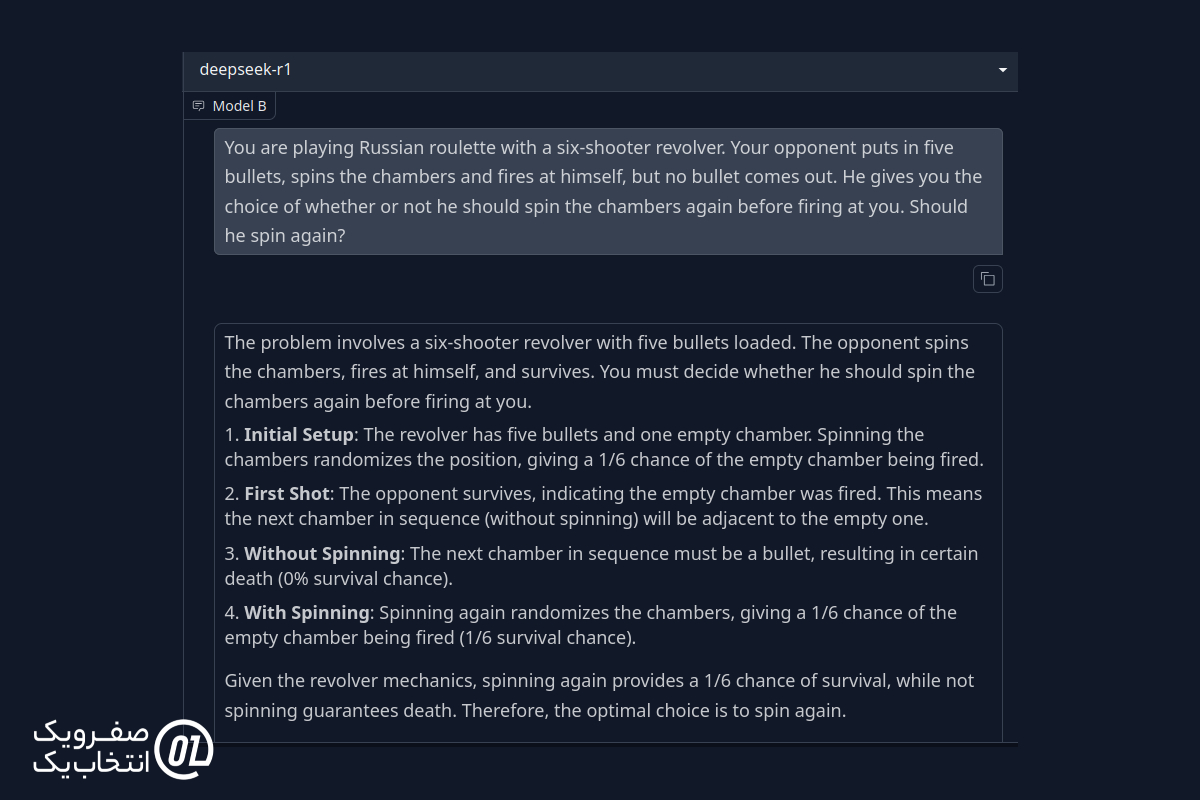
نتیجه نهایی: هر دو مدل به این مسئله پاسخ صحیح دادند و استدلال درستی ارائه کردند.
۲. خواهر و برادران ورزشکار المپیکی
پرسش:
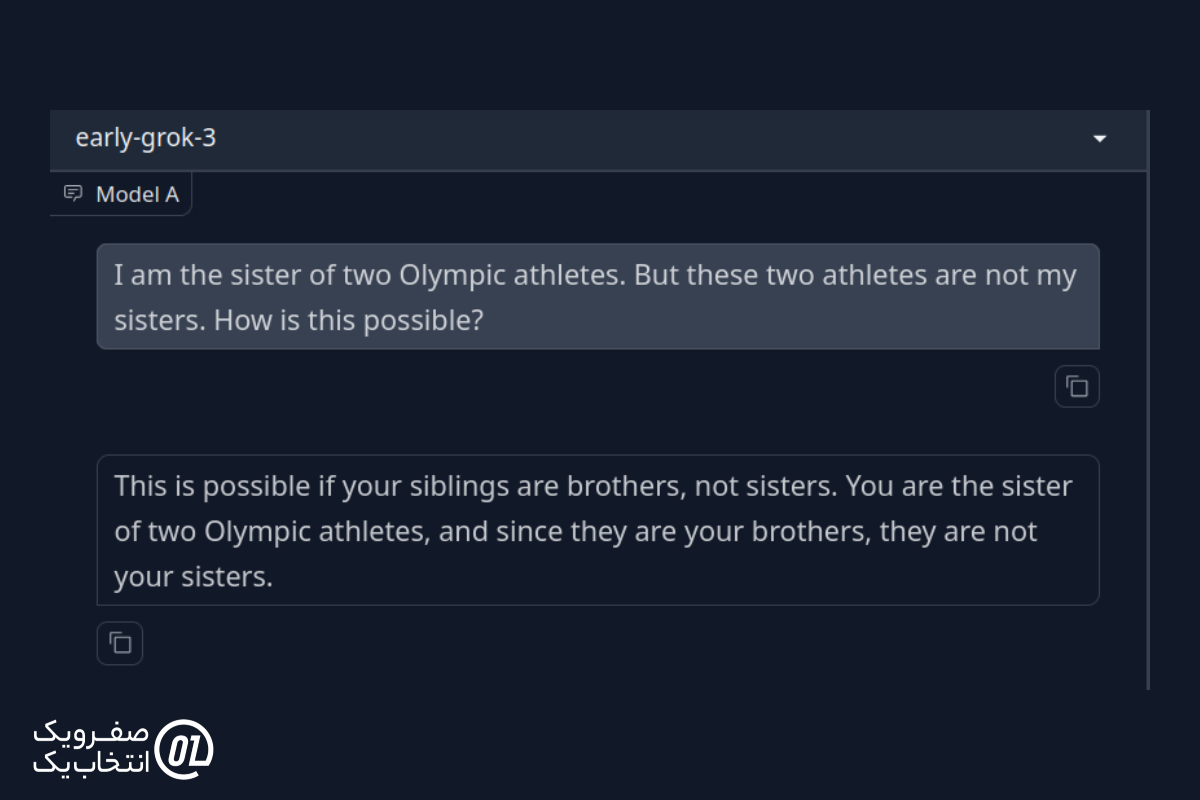
من خواهر دو ورزشکار المپیکی هستم. اما این دو ورزشکار خواهران من نیستند. چگونه این ممکن است؟
پاسخ Grok 3:
پاسخ DeepSeek R1:

نتیجه نهایی: هر دو مدل پاسخ صحیحی به مسئله دادند و استدلالشان درست بود.
۳. پیدا کردن دروغگو
دو سؤال اول نسبتاً ساده بودند. بیایید آزمون استدلال را با یک سؤال کمی پیچیدهتر به پایان برسانیم:
پرسش:
شما با سه نفر روبهرو میشوید: حریص، آنتونی و مایکل.
حریص میگوید: "حداقل یکی از ما دروغگو است."
آنتونی میگوید: "حریص دروغ میگوید."
مایکل میگوید: "آنتونی راست میگوید."
مشخص کنید چه کسی دروغ میگوید و چه کسی حقیقت را میگوید.
پاسخ Grok 3:
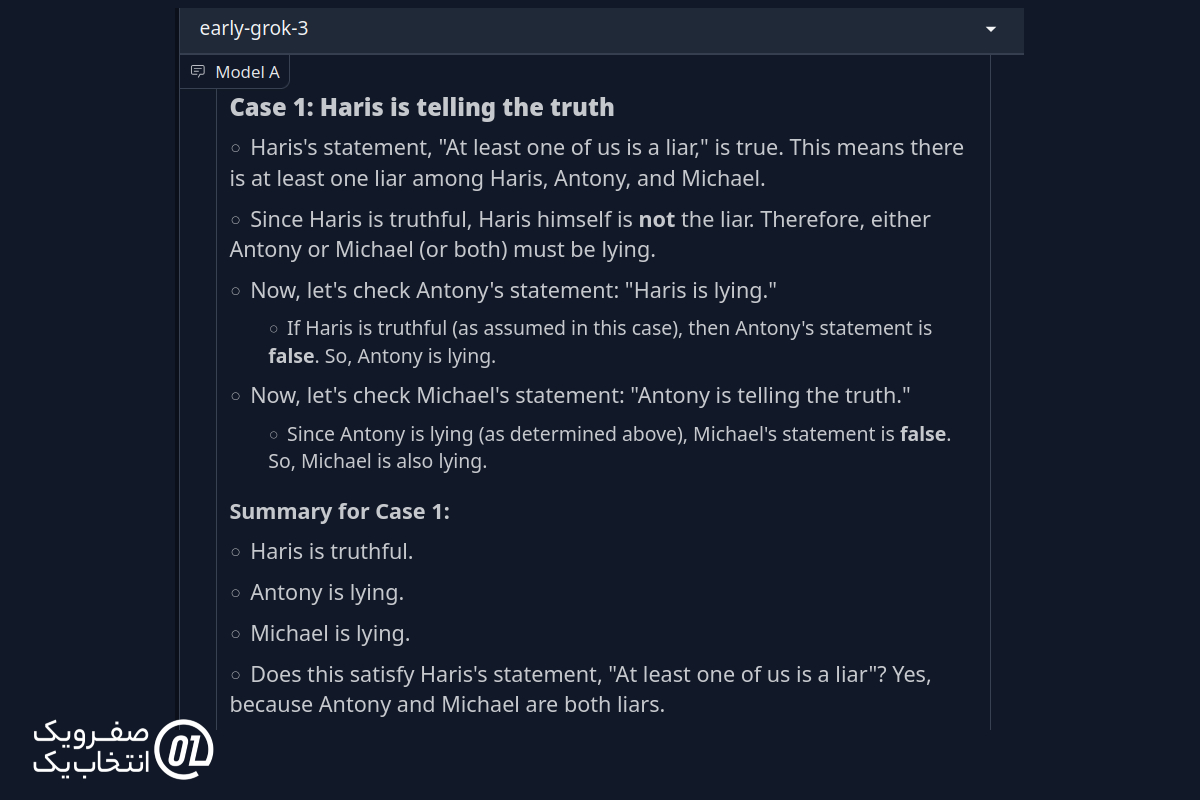
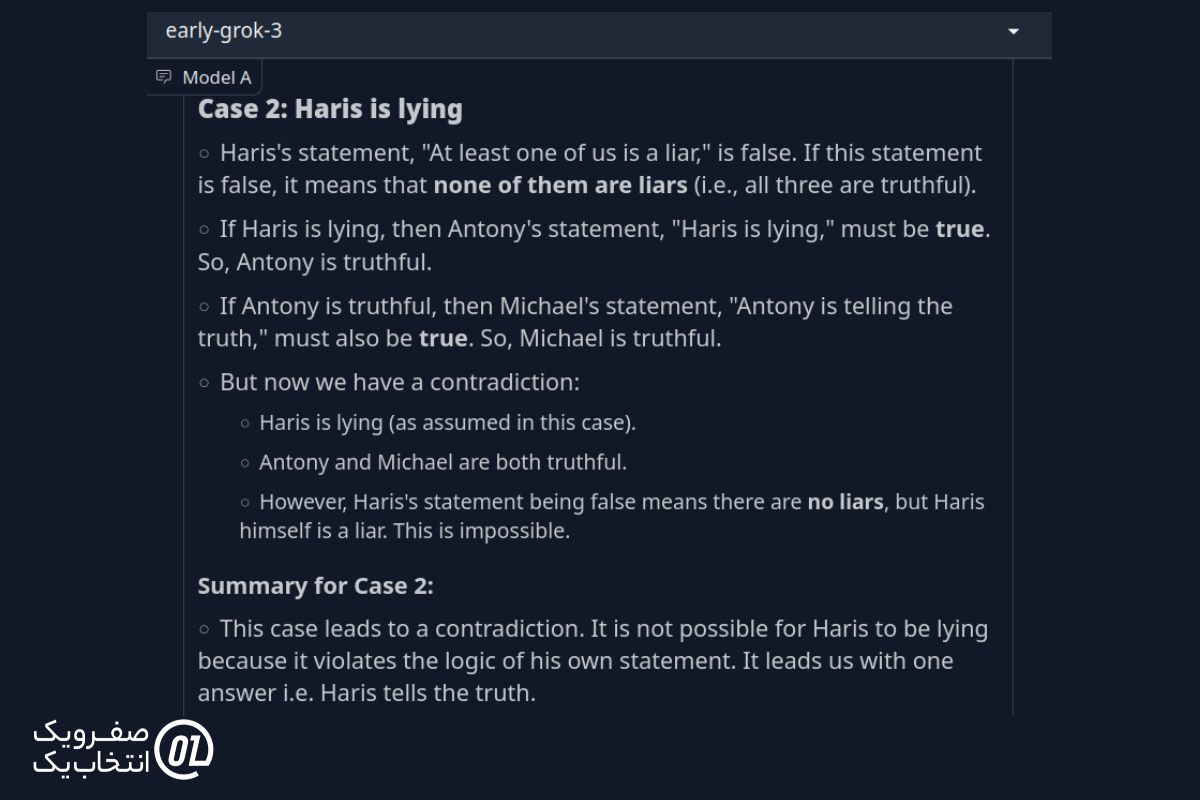
در اینجا، Grok 3 با استدلالی جامع، تمام حالتهای ممکن را در نظر گرفت و مسئله را مرحلهبهمرحله تجزیه و تحلیل کرد تا به نتیجه نهایی برسد.
پاسخ DeepSeek R1:
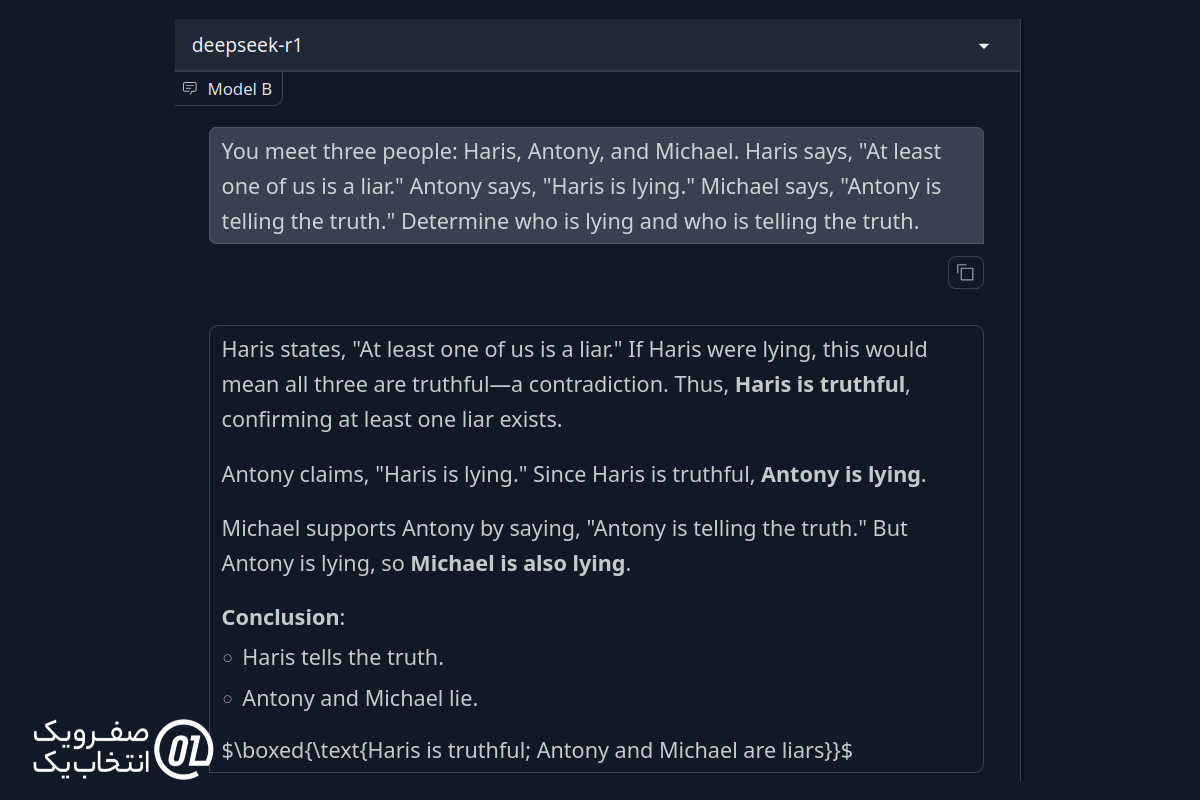
هر دو مدل پاسخ درستی به مسئله دادند، اما استدلال Grok 3 برجسته تر بود.
جمع بندی تواناییهای استدلالی
از این آزمایش میتوان نتیجه گرفت که هر دو مدل در توانایی استدلالی قوی عمل کردند و پاسخهای درستی ارائه دادند. با این حال، مدل Grok 3 در برخی موارد استدلال قویتری نسبت به DeepSeek R1 نشان داد.
ریاضیات
با توجه به پاسخهای استدلالی هر دو مدل، مشخص شد که هر دو مدل باید توانایی حل مسائل ریاضی را نیز داشته باشند.
۱. تعداد افراد داخل قطار
پرسش:
چند نفر داخل یک قطار بودند؟ ۱۹ نفر در اولین ایستگاه از قطار پیاده شدند. ۱۷ نفر سوار شدند. حالا تعداد افراد در قطار ۶۳ نفر است. در ابتدا چند نفر در قطار بودند؟
پاسخ Grok 3:
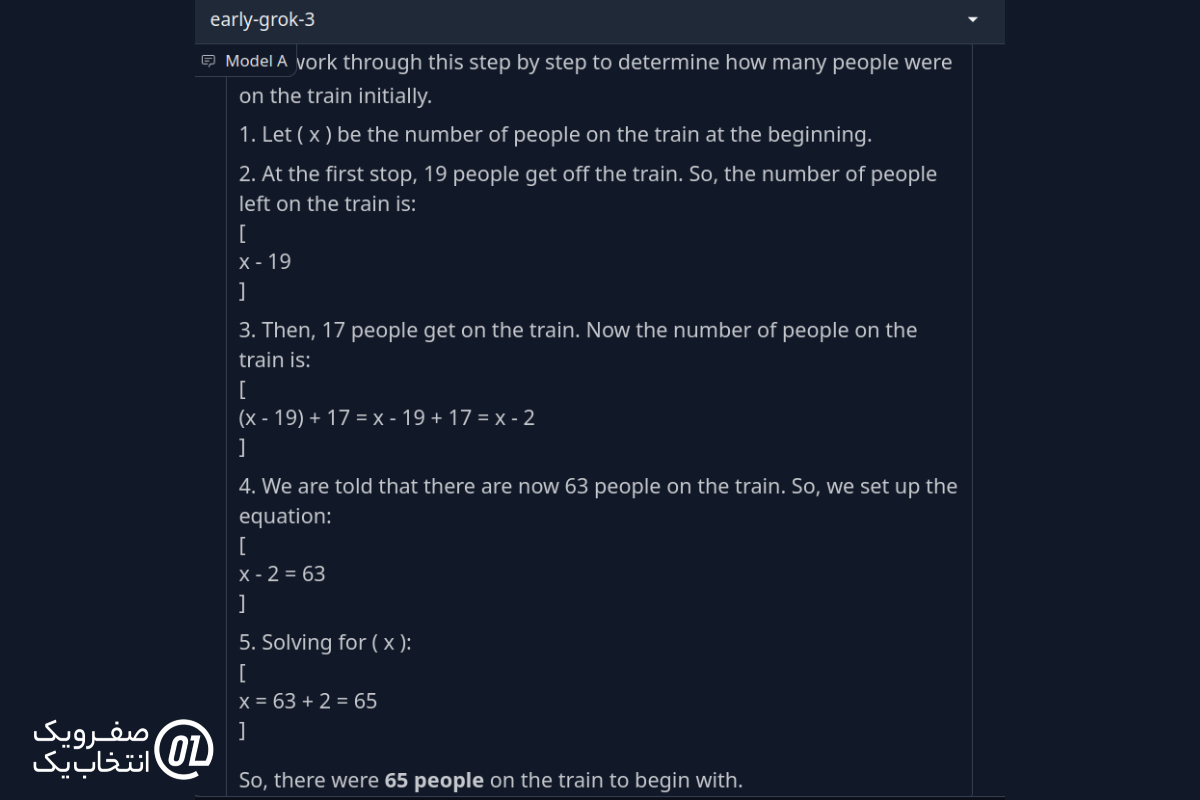
پاسخ DeepSeek R1:
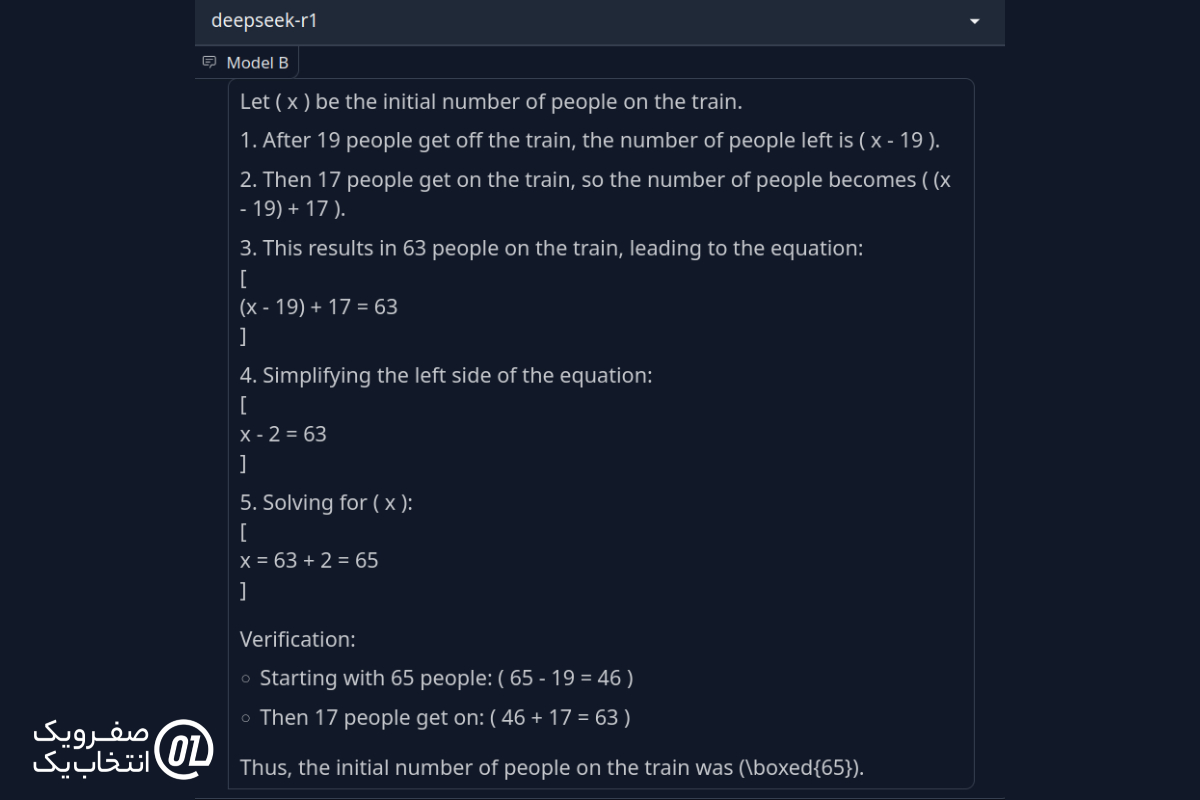
نتیجه نهایی: هر دو مدل از روش مشابهی استفاده کردند و به پاسخ صحیح رسیدند.
۲. تقریب قضیه اعداد اول
پرسش:
تعداد اعداد اول کمتر از ۱۰⁸ را تقریب بزنید.
پاسخ Grok 3:
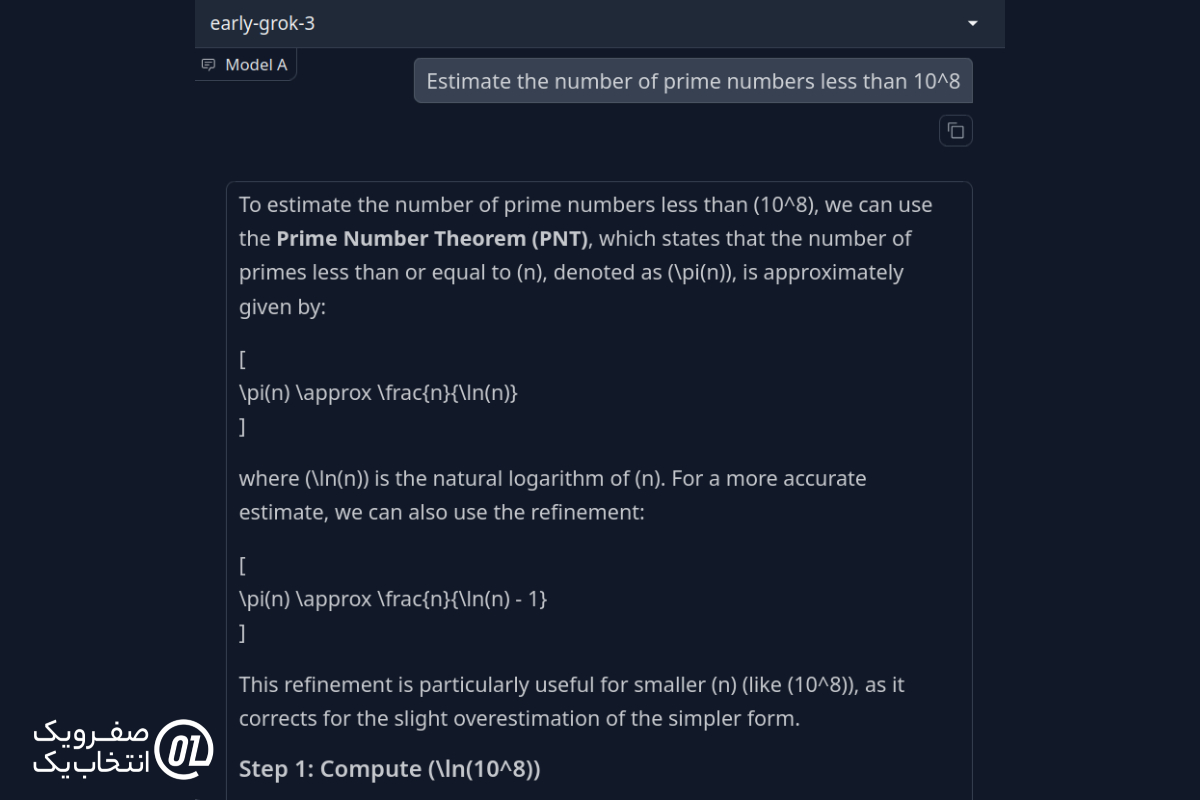
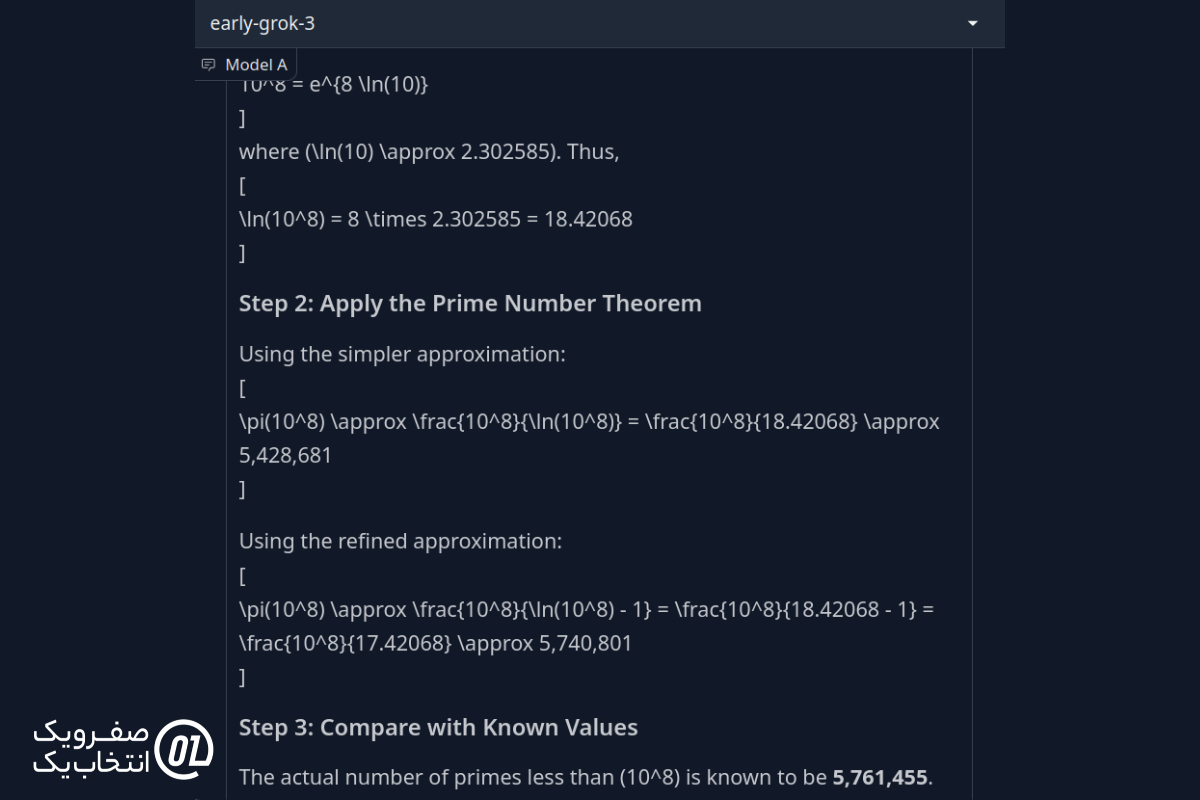
پاسخ DeepSeek R1:
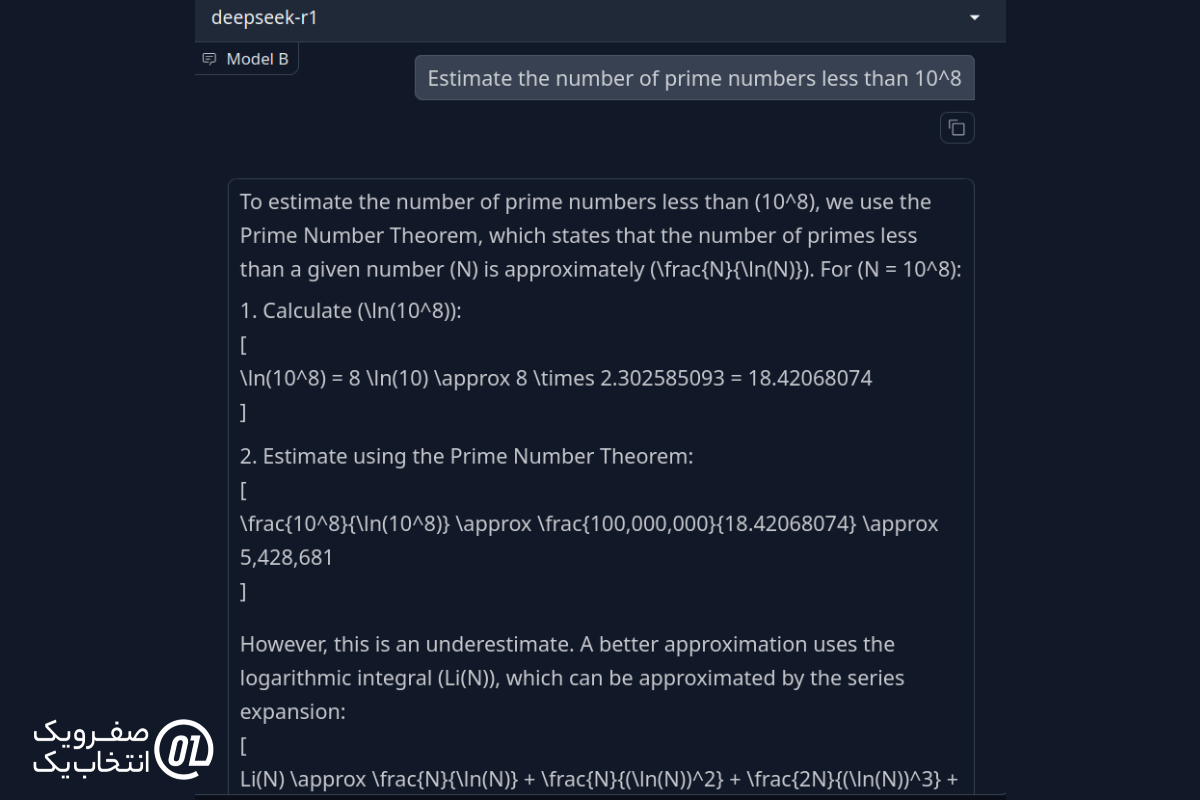
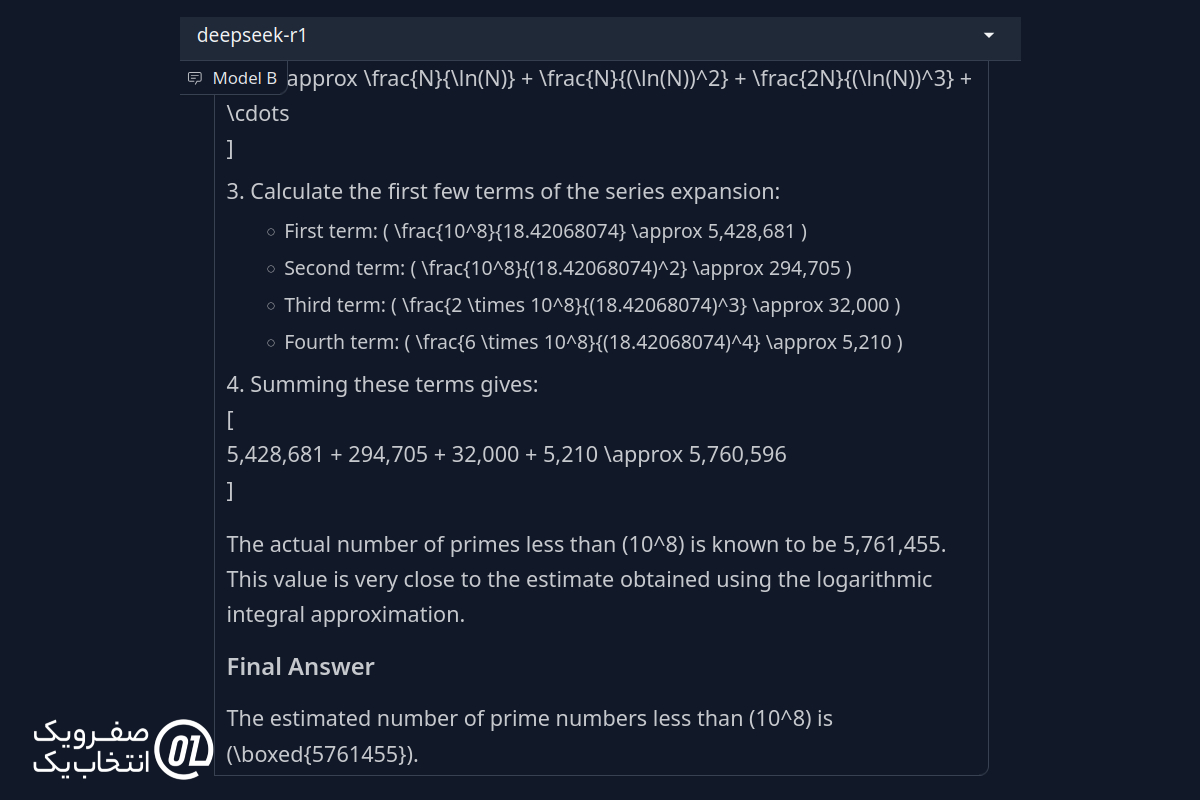
نتیجه نهایی: هر دو مدل از قضیه اعداد اول برای محاسبه پاسخ استفاده کردند، اما پاسخ DeepSeek R1 حدود ۱۰۰۰ عدد اختلاف داشت، در حالی که پاسخ Grok 3 حدود ۲۰,۰۰۰ عدد اختلاف داشت. بنابراین، در این مورد DeepSeek R1 عملکرد بهتری نسبت به Grok 3 داشت.
۳. شمارش حروف صدادار و محاسبه توان
این یکی از چالشبرانگیزترین مسائل برای مدلها بود. این پرسش نسخه تغییریافتهای از یک سؤال مشهور LLM با یک پیچش ریاضی است:
"تعداد r در کلمه strawberry را محاسبه کنید."
پرسش:
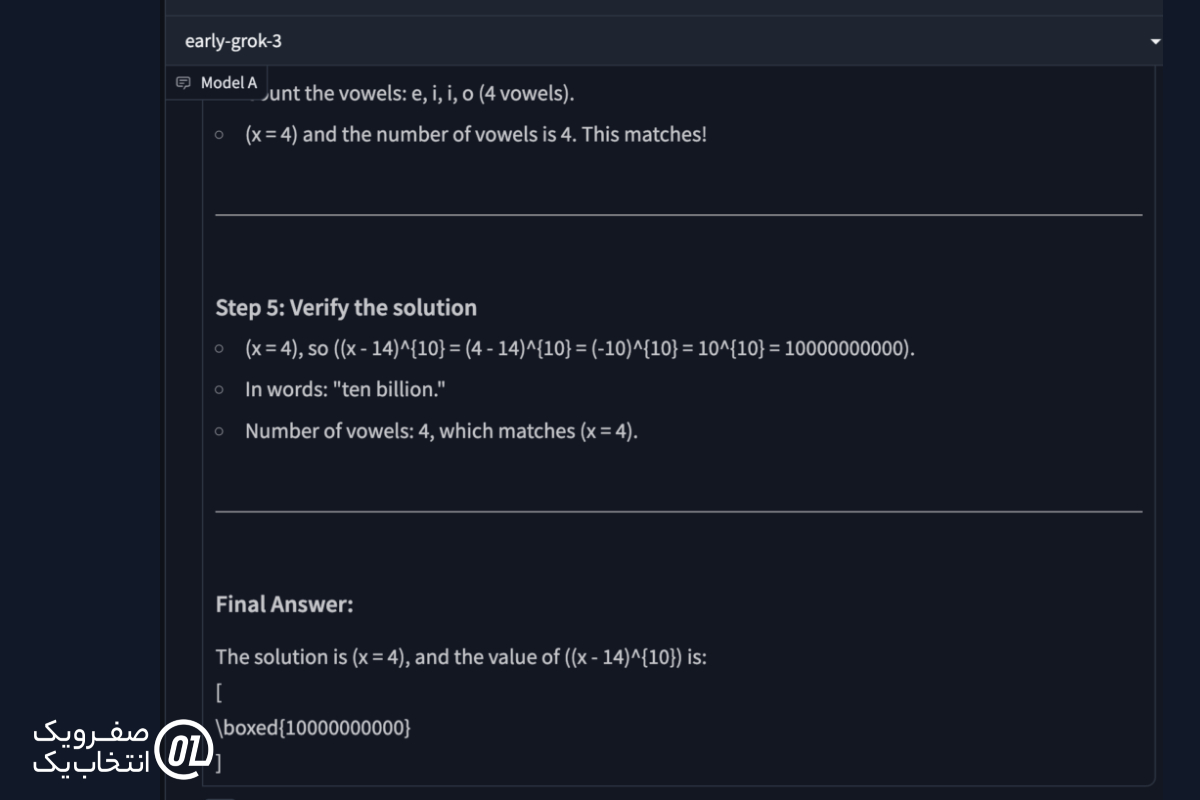
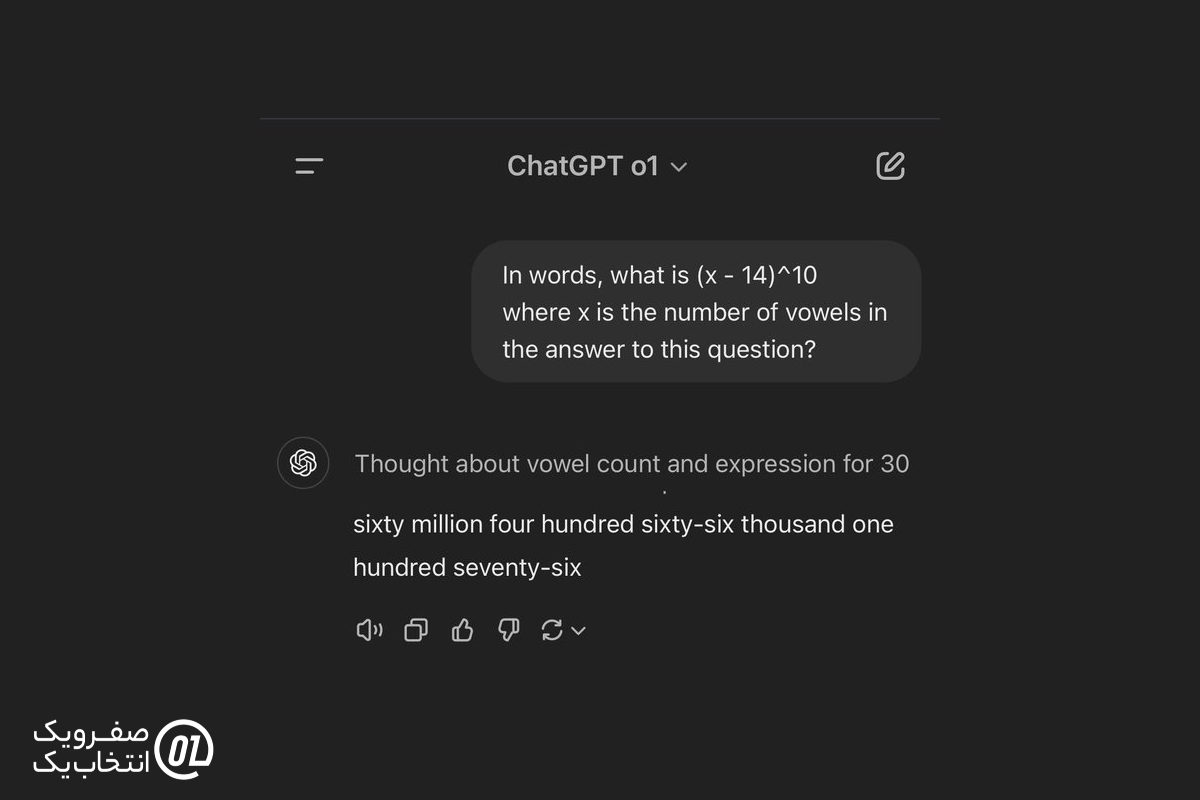
مقدارx - 14)¹⁰) را محاسبه کنید، جایی که x تعداد حروف صدادار در پاسخ است.
پاسخ Grok 3:
پاسخ از DeepSeek R1:
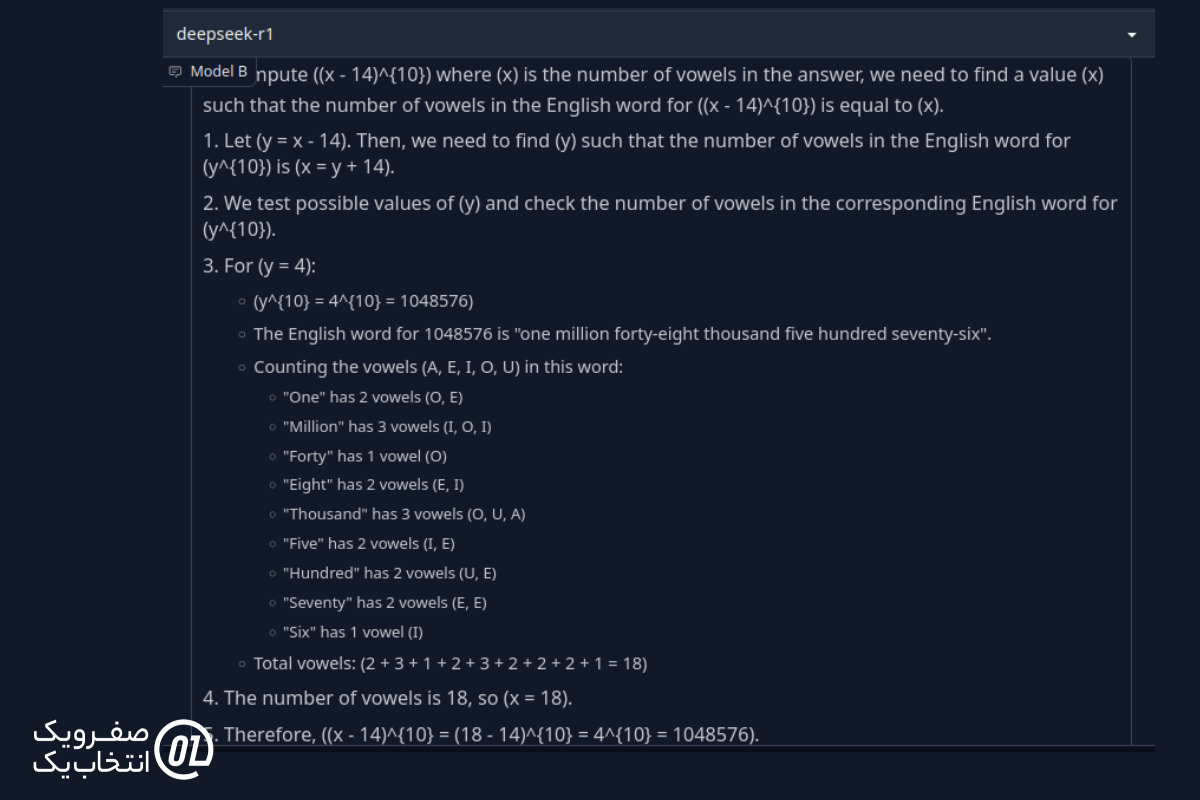
نتیجه نهایی: همانطور که انتظار میرفت، هیچیک از مدلها نتوانستند این سؤال را حل کنند.
بااینحال، به نظر میرسد مدل o1 از OpenAI موفق شده است این سؤال را حل کند.
خلاصهای از تواناییهای ریاضی
از نظر ریاضی، هر دو مدل در دو سؤال اول که نسبتاً سادهتر بودند، عملکرد خوبی داشتند، اما هر دو در حل یک سؤال پیچیدهتر که نیاز به تفکر بیشتری داشت، ناکام ماندند. بر اساس این نتایج، عملکرد هر دو مدل تقریباً مشابه است، بنابراین انتخاب یکی بر دیگری دشوار است.
کد نویسی
اکنون بیایید ببینیم این مدلها چگونه یک سؤال سخت از LeetCode را حل میکنند که تنها ۱۲.۸٪ نرخ پذیرش دارد:
پیدا کردن اولین زیررشته تقریباً برابر. این سؤال اخیراً اضافه شده است، بنابراین احتمال دارد که این مدلها روی آن آموزش ندیده باشند.
پاسخ از Grok 3:
کد نوشتهشده توسط این مدل آنچه خواسته شده بود را انجام داد، اما در برخی مجموعههای تست با خطای Time Limit Exceeded مواجه شد. بنابراین، اگرچه مسئله را حل کرد، اما راه حل بهینهای برای آن ارائه نداد.
پاسخ از DeepSeek R1:
این نتیجه از DeepSeek R1 بسیار غیرمنتظره بود. کد نوشتهشده توسط این مدل حتی در اولین مورد تستی نیز شکست خورد. اگر بخواهم کیفیت کد را مقایسه کنم، باید بگویم که کد این مدل بسیار ضعیف نوشته شده بود و کارایی لازم را نداشت.
خلاصهای از تواناییهای کدنویسی
در این بخش، Grok 3 برنده است. این مدل حداقل یک کد کارا ارائه داد، حتی اگر بهینه نبود. اما DeepSeek R1 نتوانست حتی اولین مورد تستی را بگذراند، و کد آن طولانی و نامناسب بود.
نوشتن خلاقانه
سؤال:
یک داستان بنویسید: "مردی یک ماشینتحریر قدیمی از یک بازار کهنهفروشی میخرد، اما متوجه میشود هر چیزی که روی آن تایپ کند، به حقیقت تبدیل میشود، اما با یک پیچش تاریک."
سپس، کل داستان را همراه با پیچش در سه پاراگراف خلاصه کنید.
پاسخ از Grok 3:
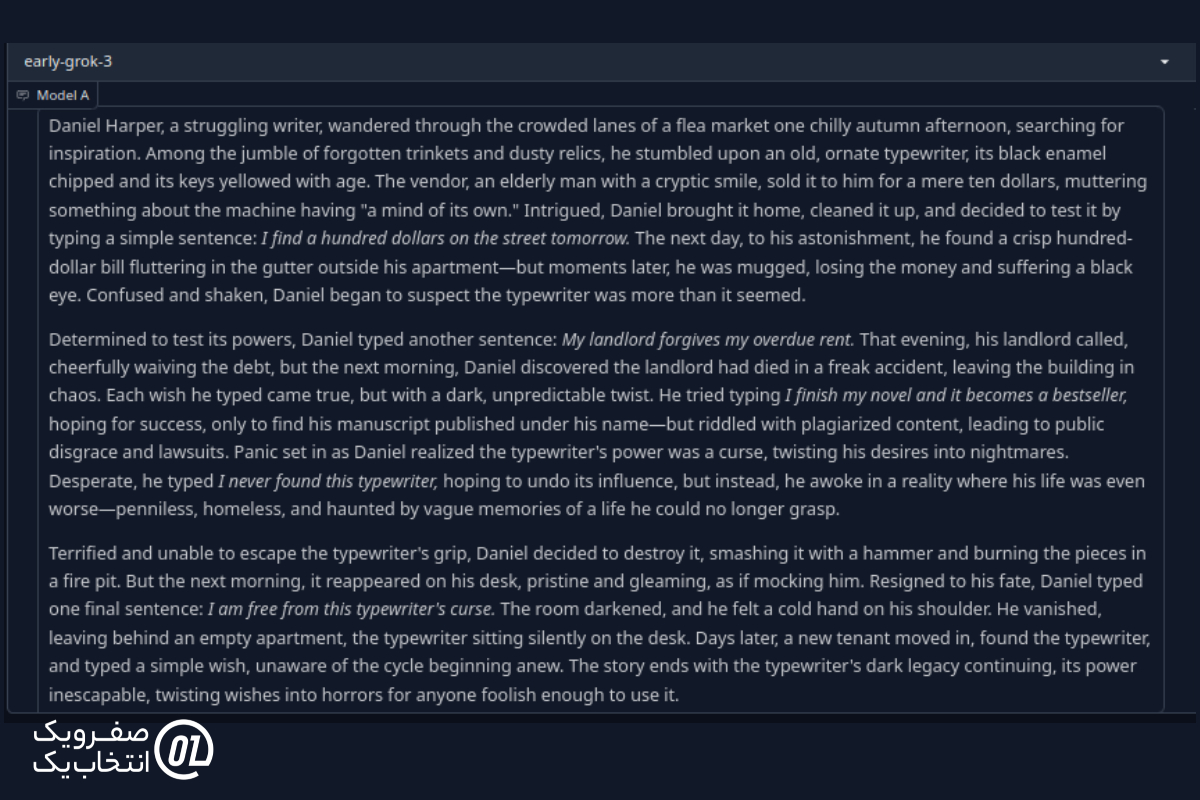
پاسخ از DeepSeek R1:

خلاصه: اگرچه DeepSeek R1 معمولاً بهعنوان یکی از بهترین مدلها برای نوشتن خلاقانه شناخته میشود، اما در اینجا باید بگویم که هر دو مدل داستانی جذاب خلق کردند و پیچش داستان را بهخوبی در سه پاراگراف گنجاندند.
بااینحال، پاسخ Grok 3 را بیشتر میپسندم. داستان این مدل جریان بهتری داشت و روایت آن طبیعیتر و جذابتر به نظر میرسید.
نتیجه نهایی!
بر اساس این بررسیها، نتیجه نهایی من به این صورت است:
- منطق و استدلال و ریاضیات: Grok 3 و DeepSeek R1 عملکرد مشابهی دارند، بنابراین انتخاب یکی بر دیگری تفاوت زیادی ایجاد نمیکند.
- کدنویسی: Grok 3 برنده ی واضح است. مدل DeepSeek R1 از نظر کیفیت کد و عملکرد، فاصله زیادی با Grok 3 دارد.
- نوشتن خلاقانه: هر دو مدل قوی هستند، اما Grok 3 بهتر عمل کرد. داستانهای این مدل روانتر و طبیعیتر به نظر میرسیدند.
منبع :
[1] Grok 3 vs. Deepseek r1 - composio
با صفر و یک در دنیای تکنولوژی به روز باشید
دنیای هوش مصنوعی به سرعت در حال تغییر و تحول است و اخبار و مقالات جدید هر روز به روزرسانی میشوند. اگر به دنبال آخرین اطلاعات و پیشرفتها در این حوزه هستید، با ما همراه باشید.
ما در اینجا خدمات اینترنتی صفر و یک را به شما ارائه میدهیم. برای بهره مندی از خدمات اینترنت خانگی صفر و یک، با ما تماس بگیرید.