لیست مطالب
- دیپ لرنینگ چیست؟
- مفاهیم اصلی دیپ لرنینگ
- اهمیت دیپ لرنینگ در چیست؟
- مزایای یادگیری عمیق
- انواع مدلهای یادگیری عمیق
- چهار مدل مهم Deep Learning
- کاربردهای دیپ لرنینگ چیست؟
- یادگیری عمیق چگونه کار میکند؟
- از ماشین لرنینگ تا دیپ لرنینگ
- هوش مصنوعی و دیپ لرنینگ
- الگوریتمهای محبوب دیپ لرنینگ چیست؟
- بهترین ابزارها و فریم ورکها برای یادگیری عمیق
- چالشها و محدودیتهای یادگیری عمیق
- دورنما و آینده یادگیری عمیق
- دنیای صفر و یک
یادگیری عمیق یا Deep Learning یکی از شاخههای پیشرفته و مهم یادگیری ماشین (Machine Learning) است که با استفاده از شبکههای عصبی مصنوعی، توانایی تحلیل و یادگیری از دادههای پیچیده را فراهم میکند. این فناوری به دلیل پیشرفتهای چشمگیر در قدرت محاسباتی، دسترسی به دادههای بزرگ و توسعه الگوریتمهای پیشرفته، به یکی از ابزارهای کلیدی در حوزه هوش مصنوعی تبدیل شده است. یادگیری عمیق در بسیاری از زمینهها مانند پردازش تصویر، پردازش زبان طبیعی، تشخیص صدا، خودروهای خودران و حتی پزشکی، انقلابی ایجاد کرده است و به دلیل دقت و کارایی بالا، به سرعت در حال گسترش است.
دیپ لرنینگ چیست؟
دیپ لرنینگ به مجموعه ای از الگوریتمها گفته میشود که از ساختار شبکههای عصبی مصنوعی (Artificial Neural Networks) الهام گرفتهاند. این الگوریتمها با استفاده از لایههای متعدد (عمیق) از نورونها، دادهها را پردازش کرده و الگوهای پیچیده را شناسایی میکنند. برخلاف روشهای سنتی یادگیری ماشین که نیاز به استخراج ویژگیهای دستی دارند، دیپ لرنینگ به صورت خودکار ویژگیهای مهم را از دادهها استخراج میکند. این ویژگی باعث شده است که دیپ لرنینگ در مسائل پیچیدهای که نیاز به تحلیل دادههای غیرساختار یافته مانند تصاویر، ویدئوها و صداها دارند، عملکرد بسیار بهتری داشته باشد.
به بیان دیگر، دیپ لرنینگ به مدلها این امکان را میدهد که با استفاده از لایههای متعدد، دادهها را به صورت سلسله مراتبی پردازش کنند. هر لایه از شبکه عصبی، ویژگیهای خاصی از دادهها را استخراج کرده و به لایه بعدی منتقل میکند. این فرآیند باعث میشود که مدل بتواند الگوهای پیچیده و پنهان در دادهها را شناسایی کند و در نهایت خروجی دقیقی ارائه دهد.
دیپ لرنینگ به دلیل توانایی در یادگیری از دادههای بزرگ و پیچیده، به یکی از ابزارهای اصلی در توسعه سیستمهای هوشمند تبدیل شده است. این فناوری نه تنها در حوزههای علمی و صنعتی، بلکه در زندگی روزمره ما نیز تأثیرات قابل توجهی داشته است.
مفاهیم اصلی دیپ لرنینگ

دیپ لرنینگ یا یادگیری عمیق بر پایه شبکههای عصبی مصنوعی بنا شده است که از ساختار مغز انسان الهام گرفتهاند. این مفاهیم شامل شبکههای عصبی، شبکههای عصبی عمیق و توابع فعال سازی هستند که هر کدام نقش مهمی در عملکرد این فناوری دارند.
شبکههای عصبی
شبکههای عصبی مصنوعی (Artificial Neural Networks) یکی از اصلیترین اجزای دیپ لرنینگ هستند. این شبکهها از نورونهای مصنوعی تشکیل شدهاند که به صورت لایهای سازمان دهی شدهاند و دادهها را پردازش میکنند. هر نورون ورودیهایی دریافت میکند، آنها را وزندهی کرده و از طریق یک تابع فعال سازی خروجی تولید میکند. شبکههای عصبی قادر به شناسایی الگوها و روابط پیچیده در دادهها هستند و به همین دلیل در مسائل مختلفی مانند تشخیص تصویر و پردازش زبان طبیعی کاربرد دارند.
شبکههای عصبی عمیق
شبکههای عصبی عمیق (Deep Neural Networks) نسخه پیشرفته تر شبکههای عصبی هستند که شامل چندین لایه پنهان (Hidden Layers) میشوند. این لایهها به مدل اجازه میدهند تا دادههای پیچیده تر را پردازش کند و ویژگیهای سطح بالا را شناسایی کند. هرچه تعداد لایهها بیشتر باشد، مدل توانایی بیشتری در یادگیری الگوهای پیچیده خواهد داشت. این ساختار عمیق، دیپ لرنینگ را از یادگیری ماشین سنتی متمایز میکند و آن را برای مسائل پیچیده تر مناسب میسازد.
توابع فعال سازی
توابع فعال سازی (Activation Functions) یکی از اجزای کلیدی شبکههای عصبی هستند که تصمیم میگیرند نورونها فعال شوند یا خیر. این توابع غیرخطی مانند ReLU، Sigmoid و Tanh به مدل کمک میکنند تا روابط پیچیده و غیرخطی را در دادهها شناسایی کند. بدون این توابع، شبکههای عصبی تنها قادر به یادگیری روابط خطی بودند و نمیتوانستند مسائل پیچیده را حل کنند.
اهمیت دیپ لرنینگ در چیست؟
دیپ لرنینگ به دلیل توانایی در پردازش دادههای پیچیده و غیرساختار یافته، به یکی از مهمترین ابزارهای هوش مصنوعی تبدیل شده است. این فناوری با استفاده از شبکههای عصبی عمیق، قادر است الگوهای پنهان در دادهها را شناسایی کرده و مسائل پیچیده را حل کند. از کاربردهای مهم آن میتوان به تشخیص بیماریها در پزشکی، توسعه خودروهای خودران، پردازش زبان طبیعی و تشخیص چهره اشاره کرد. دیپ لرنینگ همچنین در اتوماسیون وظایف تحلیلی و فیزیکی بدون دخالت انسان نقش کلیدی دارد و به دلیل دقت بالا و قابلیت تعمیم پذیری، در بسیاری از صنایع جایگاه ویژهای پیدا کرده است.

مزایای یادگیری عمیق
یادگیری عمیق به عنوان یکی از پیشرفته ترین شاخههای هوش مصنوعی، توانسته است با ارائه راهکارهای مؤثر در پردازش دادههای پیچیده، جایگاه ویژهای در بسیاری از حوزههای علمی و صنعتی به دست آورد. توانایی پردازش دادههای غیرساختار یافته، دقت بالا در حل مسائل پیچیده و سازگاری با منابع محاسباتی مدرن، از جمله ویژگیهایی هستند که یادگیری عمیق را به یک ابزار قدرتمند تبدیل کردهاند. در ادامه، به بررسی مهم ترین مزایای یادگیری عمیق می پردازیم.
عملکرد بی نظیر در دادههای غیرساختار یافته
یکی از بزرگ ترین مزایای یادگیری عمیق، توانایی آن در پردازش و تحلیل دادههای غیرساختار یافته است. دادههای غیرساختار یافته شامل تصاویر، ویدئوها، صداها، و متون هستند که به طور گسترده در دنیای واقعی وجود دارند. برخلاف الگوریتمهای سنتی یادگیری ماشین که معمولاً در پردازش این نوع دادهها محدودیت دارند، مدلهای دیپ لرنینگ با استفاده از شبکههای عصبی عمیق میتوانند به طور خودکار الگوهای پیچیده را از این دادهها استخراج کنند. به عنوان مثال، در پردازش تصویر، دیپ لرنینگ میتواند اشیاء، چهرهها و حتی احساسات را با دقت بالا تشخیص دهد. در حوزه صوت و گفتار نیز، این فناوری در کاربردهایی مانند تبدیل گفتار به متن و تشخیص گوینده عملکرد بینظیری دارد.
خودکارسازی فرآیند استخراج ویژگی
یکی از مشکلات اصلی روشهای سنتی یادگیری ماشین، نیاز به استخراج دستی ویژگیها از دادهها بود. دیپ لرنینگ این چالش را با خودکارسازی فرآیند استخراج ویژگیها حل کرده است. مدلهای یادگیری عمیق با استفاده از لایههای مختلف شبکههای عصبی، میتوانند به طور خودکار ویژگیهای مهم و مرتبط را از دادهها استخراج کنند. این فرآیند نه تنها باعث صرفه جویی در زمان و منابع انسانی میشود، بلکه دقت و کارایی مدلها را نیز افزایش میدهد. به عنوان مثال، در مسائل پردازش تصویر، مدلهای دیپ لرنینگ به صورت خودکار ویژگیهایی مانند لبهها، بافتها و اشیاء را استخراج میکنند، بدون اینکه نیاز به دخالت انسان باشد.
دقت بالا در مسائل پیچیده

مدلهای دیپ لرنینگ به دلیل ساختار چند لایه و توانایی یادگیری از دادههای بزرگ، در حل مسائل پیچیده عملکرد بسیار دقیقی دارند. این فناوری در حوزههایی مانند تشخیص چهره، ترجمه زبان، و پیشبینیهای پزشکی، توانسته است به دقتی فراتر از روشهای سنتی دست یابد. به عنوان مثال، در تشخیص بیماریها از تصاویر پزشکی، مدلهای دیپ لرنینگ میتوانند علائم بیماری را با دقت بالا شناسایی کنند و در برخی موارد حتی بهتر از پزشکان عمل کنند. همچنین در ترجمه زبانهای مختلف، این مدلها توانستهاند ترجمهای روان تر و طبیعی تر ارائه دهند.
مقیاس پذیری بالا
یادگیری عمیق به دلیل توانایی در پردازش حجم وسیعی از دادهها، از مقیاس پذیری بالا برخوردار است. این فناوری به راحتی میتواند با دادههای بزرگ و منابع محاسباتی مدرن ترکیب شود و عملکرد خود را حفظ کند. به عنوان مثال، با افزایش دادههای آموزشی، مدلهای دیپ لرنینگ میتوانند دقت خود را بهبود بخشند. این ویژگی باعث شده است که دیپ لرنینگ در کاربردهایی مانند تحلیل رفتار کاربران در شبکههای اجتماعی یا مدیریت دادههای بزرگ در سازمانها، بسیار مؤثر باشد.
قابلیت تعمیم پذیری بالا
یکی دیگر از مزایای مهم دیپ لرنینگ، قابلیت تعمیم پذیری بالا است. مدلهای دیپ لرنینگ به خوبی میتوانند در دادههای جدید و ناشناخته عملکرد داشته باشند. این قابلیت به ویژه در مسائل پیچیدهای که تنوع دادهها زیاد است، بسیار ارزشمند است. برای مثال، یک مدل دیپ لرنینگ که برای تشخیص چهره آموزش دیده است، میتواند با دقت بالا چهرههای جدید و ناشناخته را نیز شناسایی کند. این ویژگی باعث میشود که دیپ لرنینگ در حل مسائل واقعی و دنیای غیرقطعی بسیار کارآمد باشد.
سازگاری با منابع محاسباتی مدرن
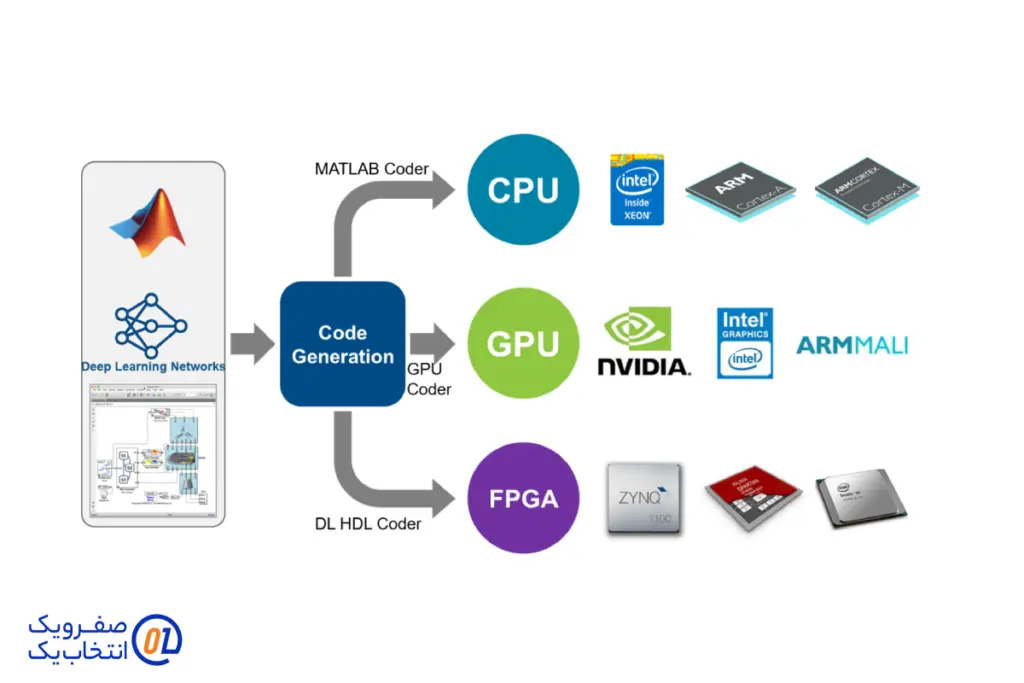
دیپ لرنینگ از GPU و TPU برای تسریع فرآیند پردازش و آموزش مدلها استفاده میکند. این سختافزارها، به دلیل توانایی بالا در انجام محاسبات موازی، سرعت آموزش مدلهای دیپ لرنینگ را به میزان قابل توجهی افزایش دادهاند. این سازگاری با منابع محاسباتی مدرن، امکان پردازش دادههای بزرگ و پیچیده را فراهم کرده و به توسعه سریع تر پروژههای مبتنی بر دیپ لرنینگ کمک میکند. این ویژگی به ویژه در برنامههای کاربردی مانند خودروهای خودران و سیستمهای توصیه گر که نیاز به پردازش لحظه ای دادهها دارند، بسیار مهم است.
پیشرفتهای مستمر و به روزرسانی مداوم
دیپ لرنینگ یکی از حوزههایی است که به طور مداوم در حال تحقیق و توسعه است. هر ساله الگوریتمهای جدید، ابزارهای پیشرفتهتر و بهبودهای عملکردی مهمی به این حوزه اضافه میشود. این پیشرفتها باعث میشود که دیپ لرنینگ همواره در خط مقدم فناوری باشد و بتواند به نیازهای روزافزون صنایع مختلف پاسخ دهد. به عنوان مثال، با معرفی معماریهای جدید مانند ترنسفورمرها (Transformers)، پیشرفتهای چشمگیری در پردازش زبان طبیعی و بینایی کامپیوتری حاصل شده است.
انواع مدلهای یادگیری عمیق
یادگیری عمیق (Deep Learning) به عنوان یکی از شاخههای پیشرفته هوش مصنوعی، از مدلهای مختلفی برای حل مسائل متنوع استفاده میکند. این مدلها بر اساس نوع دادهها و هدف مسئله به دستههای مختلفی تقسیم میشوند. دو نوع اصلی یادگیری عمیق شامل یادگیری نظارت شده و یادگیری نظارتنشده است که هر کدام کاربردها و ویژگیهای خاص خود را دارند. در ادامه، این دو نوع یادگیری و زیرشاخههای آنها را بررسی میکنیم.
1. یادگیری نظارت شده (Supervised Learning)
در یادگیری نظارتشده، مدل با استفاده از دادههای برچسب دار آموزش میبیند. این بدان معناست که هر نمونه داده شامل ورودی و خروجی مشخصی است و مدل تلاش میکند رابطهای میان این دو برقرار کند. هدف اصلی این روش، یادگیری یک تابع است که بتواند ورودیهای جدید را به خروجیهای صحیح پیشبینی کند. یادگیری نظارتشده به دو دسته اصلی تقسیم میشود:
الف) طبقه بندی (Classification)
در مسائل طبقه بندی، هدف پیشبینی دستهبندی یا کلاس دادهها است. به عنوان مثال، تشخیص ایمیلهای اسپم از ایمیلهای عادی یا شناسایی تصاویر گربه و سگ از یکدیگر، نمونههایی از مسائل طبقه بندی هستند. مدلهای یادگیری عمیق مانند شبکههای عصبی پیچشی (CNN) در این نوع مسائل عملکرد بسیار خوبی دارند.
ب) رگرسیون (Regression)
در مسائل رگرسیون، هدف پیشبینی مقادیر عددی است. به عنوان مثال، پیش بینی قیمت خانه بر اساس ویژگیهایی مانند متراژ، تعداد اتاقها و موقعیت مکانی، یک مسئله رگرسیون است. مدلهای یادگیری عمیق میتوانند با استفاده از دادههای عددی، روابط پیچیده میان متغیرها را شناسایی کرده و پیشبینیهای دقیقی ارائه دهند.
یادگیری نظارت شده به دلیل دقت بالا و توانایی در حل مسائل مشخص، یکی از پرکاربردترین روشهای یادگیری عمیق است. با این حال، این روش نیازمند دادههای برچسب دار است که جمع آوری آنها ممکن است زمان بر و پرهزینه باشد.
2. یادگیری نظارت نشده (Unsupervised Learning)
در یادگیری نظارت نشده، مدل بدون استفاده از دادههای برچسب دار آموزش میبیند. در این روش، هدف اصلی شناسایی الگوها و ساختارهای پنهان در دادهها است. برخلاف یادگیری نظارتشده که خروجی مشخصی برای هر ورودی دارد، در یادگیری نظارت نشده مدل تلاش میکند تا شباهتها و تفاوتهای میان دادهها را شناسایی کند. این روش در مسائل زیر کاربرد دارد:
الف) خوشه بندی (Clustering)
در خوشه بندی، مدل دادهها را به گروههایی تقسیم میکند که اعضای هر گروه شباهت بیشتری به یکدیگر دارند. به عنوان مثال، تقسیم مشتریان یک فروشگاه به گروههای مختلف بر اساس رفتار خرید آنها، یک مسئله خوشه بندی است. الگوریتمهایی مانند شبکههای عصبی خودسازمانده (Self-Organizing Maps) در این زمینه استفاده میشوند.
ب) کاهش ابعاد (Dimensionality Reduction)
در مسائل کاهش ابعاد، هدف کاهش تعداد ویژگیهای دادهها بدون از دست دادن اطلاعات مهم است. این روش به ویژه در مسائل با دادههای بزرگ و پیچیده کاربرد دارد. مدلهای یادگیری عمیق مانند Autoencoders برای کاهش ابعاد دادهها استفاده میشوند و میتوانند ویژگیهای مهم را استخراج کنند.
یادگیری نظارت نشده به دلیل عدم نیاز به دادههای برچسب دار، در مسائل واقعی که برچسب گذاری دادهها دشوار است، بسیار مفید است. این روش به ویژه در تحلیل دادههای بزرگ و کشف الگوهای ناشناخته کاربرد دارد.
چهار مدل مهم Deep Learning
یادگیری عمیق (Deep Learning) به دلیل انعطاف پذیری و توانایی در حل مسائل پیچیده، از مدلها و تکنیکهای مختلفی برای بهبود عملکرد و کارایی استفاده میکند. چهار مدل مهم در یادگیری عمیق شامل انتقال یادگیری (Transfer Learning)، آموزش از ابتدا (Training from Scratch)، کاهش نرخ یادگیری (Learning Rate Decay) و رها کردن (Dropout) هستند. هر یک از این مدلها نقش مهمی در بهینهسازی فرآیند یادگیری و جلوگیری از مشکلاتی مانند بیشبرازش (Overfitting) دارند. در ادامه، این مدلها به تفصیل بررسی میشوند.
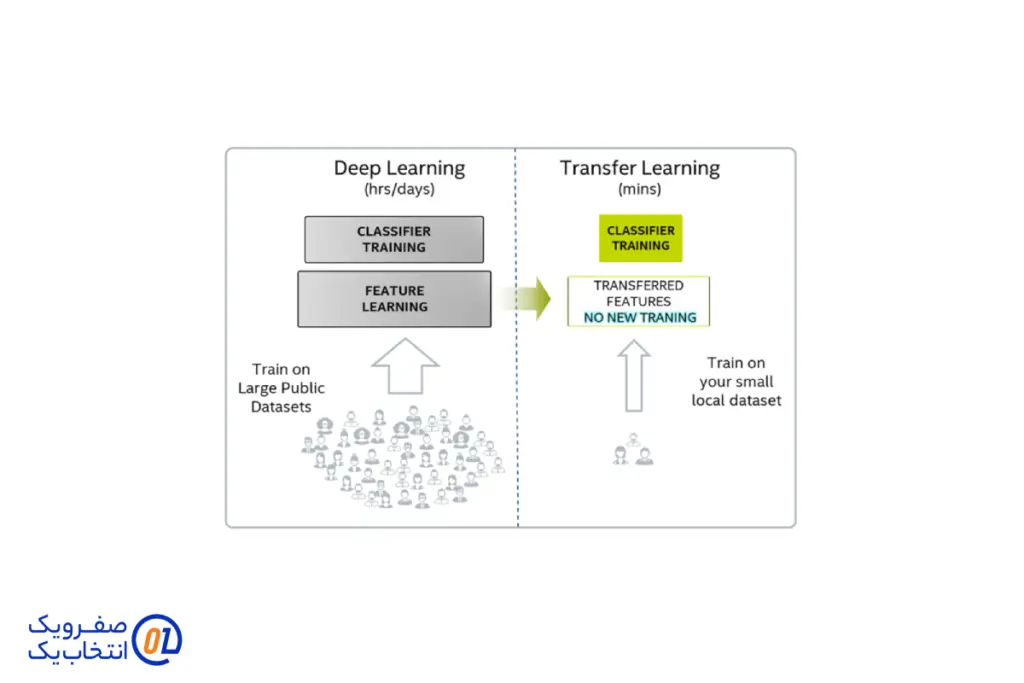
انتقال یادگیری (Transfer Learning)
انتقال یادگیری یکی از تکنیکهای پرکاربرد در یادگیری عمیق است که به معنای استفاده از یک مدل از پیش آموزشدیده برای حل مسائل جدید است. در این روش، مدلهایی که قبلاً روی مجموعه دادههای بزرگ و عمومی (مانند ImageNet) آموزش دیدهاند، به عنوان پایهای برای مسائل جدید استفاده میشوند. این تکنیک به ویژه زمانی مفید است که دادههای کافی برای آموزش مدل از ابتدا در دسترس نباشد.
برای مثال، در یک مسئله تشخیص تصویر، میتوان از یک مدل از پیش آموزشدیده مانند ResNet یا VGG استفاده کرد و تنها لایههای نهایی آن را برای مسئله خاص تنظیم کرد. این روش باعث صرفهجویی در زمان و منابع محاسباتی میشود و دقت بالایی را در مسائل جدید ارائه میدهد.
آموزش از ابتدا (Training from Scratch)
در این روش، مدل از ابتدا و با استفاده از دادههای جدید آموزش داده میشود. این تکنیک زمانی استفاده میشود که دادههای کافی و باکیفیت برای آموزش مدل در دسترس باشد و مسئله مورد نظر کاملاً متفاوت از مسائل عمومی باشد. آموزش از ابتدا نیازمند منابع محاسباتی قوی و زمان بیشتری است، زیرا مدل باید تمام ویژگیها و روابط موجود در دادهها را از ابتدا یاد بگیرد.
برای مثال، در یک پروژه خاص پزشکی که دادههای آن کاملاً منحصر به فرد هستند (مانند تصاویر MRI)، ممکن است نیاز باشد که مدل از ابتدا آموزش داده شود تا بتواند ویژگیهای خاص این دادهها را به خوبی یاد بگیرد. اگرچه این روش زمانبر است، اما در مسائل خاص و پیچیده میتواند نتایج بسیار دقیقی ارائه دهد.
کاهش نرخ یادگیری (Learning Rate Decay)
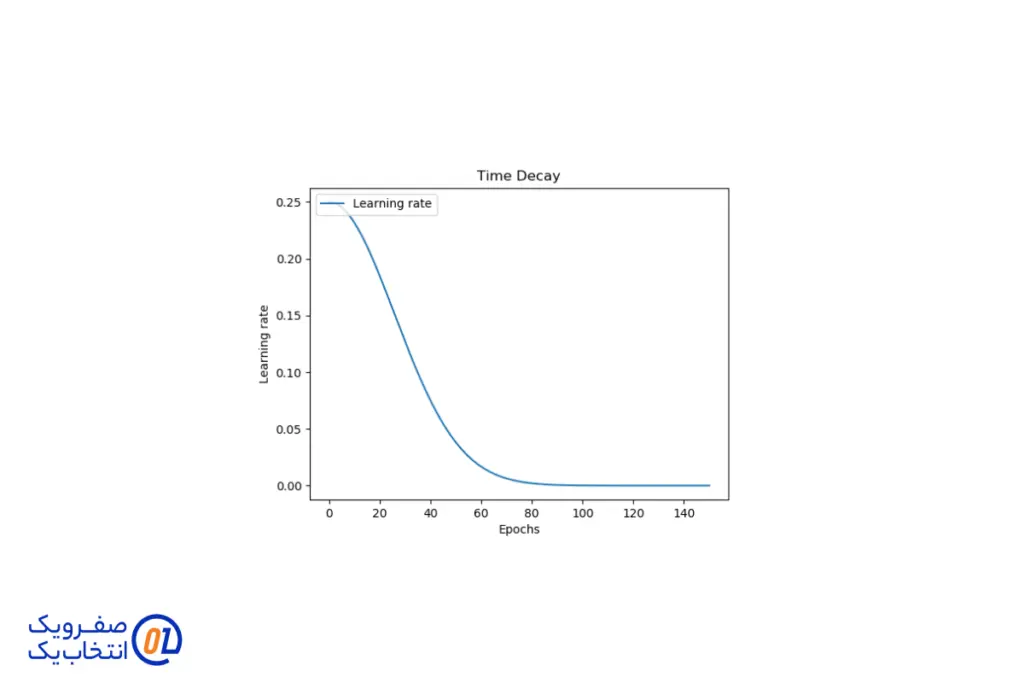
کاهش نرخ یادگیری یکی از تکنیکهای مهم در بهینهسازی مدلهای یادگیری عمیق است. نرخ یادگیری (Learning Rate) تعیین میکند که مدل با چه سرعتی وزنهای خود را در طول فرآیند آموزش به روزرسانی کند. اگر نرخ یادگیری بیش از حد بالا باشد، مدل ممکن است به یک نقطه بهینه نرسد و اگر بیش از حد پایین باشد، فرآیند آموزش بسیار کند خواهد بود.
در تکنیک کاهش نرخ یادگیری، مقدار نرخ یادگیری به تدریج در طول آموزش کاهش مییابد. این کار باعث میشود که مدل در ابتدا با سرعت بیشتری یاد بگیرد و سپس با نزدیک شدن به نقطه بهینه، تغییرات کوچکتری در وزنها ایجاد کند. این روش به بهبود دقت مدل و جلوگیری از نوسانات در فرآیند آموزش کمک میکند.
رها کردن (Dropout)
رها کردن یا Dropout یکی از تکنیکهای مؤثر برای جلوگیری از بیشبرازش (Overfitting) در مدلهای یادگیری عمیق است. در این روش، در هر مرحله از آموزش، برخی از نورونها به صورت تصادفی غیرفعال میشوند. این کار باعث میشود که مدل به جای وابستگی بیش از حد به یک مسیر خاص، از تمام مسیرهای ممکن برای یادگیری استفاده کند.
به عنوان مثال، در یک شبکه عصبی عمیق، اگر برخی از نورونها در طول آموزش غیرفعال شوند، مدل مجبور میشود که ویژگیهای مختلف را از مسیرهای دیگر یاد بگیرد. این تکنیک به افزایش تعمیمپذیری مدل کمک میکند و باعث میشود که مدل در دادههای جدید و ناشناخته عملکرد بهتری داشته باشد.
کاربردهای دیپ لرنینگ چیست؟
1. یادگیری تقویتی (Reinforcement Learning)
یکی از کاربردهای مهم دیپ لرنینگ، استفاده از آن در یادگیری تقویتی است. در این روش، مدل با تعامل با محیط و دریافت پاداش یا جریمه، یاد میگیرد که چگونه تصمیم گیری کند. این تکنیک در محیطهای پویا و پیچیده مانند بازیهای ویدئویی، رباتیک و حتی خودروهای خودران استفاده میشود. برای مثال، الگوریتمهای یادگیری تقویتی مبتنی بر دیپ لرنینگ توانستهاند در بازیهایی مانند شطرنج و Go، عملکردی بهتر از انسان ارائه دهند.
2. شبکه عصبی گراف (Graph Neural Networks)

دیپ لرنینگ در تحلیل دادههای گرافی نیز کاربرد دارد. شبکههای عصبی گراف (GNN) برای تحلیل دادههایی که به صورت گراف سازمان دهی شدهاند، مانند شبکههای اجتماعی، شبکههای حمل و نقل یا ساختارهای مولکولی، استفاده میشوند. این مدلها میتوانند ارتباطات پیچیده میان گرهها را شناسایی کرده و الگوهای پنهان را استخراج کنند. برای مثال، در شبکههای اجتماعی، GNN میتواند برای پیشبینی ارتباطات جدید یا تحلیل رفتار کاربران استفاده شود.
3. پردازش زبان طبیعی (Natural Language Processing - NLP)
یکی از برجسته ترین کاربردهای دیپ لرنینگ، پردازش زبان طبیعی (NLP) است. این فناوری در ترجمه زبان، تحلیل احساسات، خلاصه سازی متون و ساخت چتباتها کاربرد دارد. مدلهای پیشرفتهای مانند ترنسفورمرها (Transformers) و BERT توانستهاند درک زبان انسانی را به سطح جدیدی برسانند. برای مثال، Google Translate از دیپ لرنینگ برای ارائه ترجمههای دقیقتر استفاده میکند و ابزارهای تحلیل احساسات میتوانند نظرات کاربران را به صورت خودکار تحلیل کنند.
4. دستیارهای مجازی
دستیارهای مجازی مانند Siri، Google Assistant و Alexa از دیپ لرنینگ برای درک گفتار، پردازش زبان و ارائه پاسخهای مناسب استفاده میکنند. این سیستمها با تحلیل دادههای صوتی و متنی، میتوانند دستورات کاربران را اجرا کرده و تجربهای شخصیسازیشده ارائه دهند. دیپ لرنینگ به این دستیارها امکان میدهد که با گذشت زمان، عملکرد خود را بهبود بخشند و بهتر با کاربران تعامل کنند.
5. رباتهای چت (Chatbots)
رباتهای چت یکی دیگر از کاربردهای دیپ لرنینگ هستند که در خدمات مشتریان، تجارت الکترونیک و پشتیبانی فنی استفاده میشوند. این رباتها با استفاده از مدلهای NLP، میتوانند به سوالات کاربران پاسخ دهند، مشکلات آنها را حل کنند و حتی مکالمات طبیعیتری ارائه دهند. برای مثال، بسیاری از شرکتها از چتباتها برای پاسخگویی سریع به مشتریان و کاهش هزینههای پشتیبانی استفاده میکنند.
6. تشخیص چهره
تشخیص چهره یکی از کاربردهای برجسته دیپ لرنینگ در حوزه امنیت و شناسایی افراد است. این فناوری در سیستمهای نظارتی، قفلهای هوشمند و حتی شبکههای اجتماعی برای شناسایی و برچسبگذاری افراد در تصاویر استفاده میشود. مدلهای دیپ لرنینگ با تحلیل ویژگیهای چهره، میتوانند افراد را با دقت بسیار بالا شناسایی کنند.
7. خودروهای خودران

دیپ لرنینگ یکی از اجزای اصلی سیستمهای خودروهای خودران است. این فناوری با تحلیل دادههای حسگرها، دوربینها و رادارها، به خودروها امکان میدهد که محیط اطراف خود را درک کرده و تصمیمات لحظهای بگیرند. برای مثال، خودروهای تسلا از دیپ لرنینگ برای تشخیص موانع، خطوط جاده و علائم ترافیکی استفاده میکنند.
8. صنعت کشاورزی
در صنعت کشاورزی، دیپ لرنینگ برای تشخیص بیماریهای گیاهان، پیشبینی عملکرد محصولات و بهینهسازی فرآیندهای کشاورزی استفاده میشود. مدلهای یادگیری عمیق میتوانند تصاویر گیاهان را تحلیل کرده و علائم بیماریها را شناسایی کنند. این فناوری به کشاورزان کمک میکند تا بهرهوری را افزایش داده و هزینهها را کاهش دهند.
9. پردازش تصویر و تشخیص اشیاء
دیپ لرنینگ در پردازش تصویر و تشخیص اشیاء کاربرد گستردهای دارد. این فناوری در حوزههایی مانند پزشکی (برای تحلیل تصاویر پزشکی)، امنیت (برای شناسایی اشیاء مشکوک) و تبلیغات (برای تحلیل تصاویر کاربران) استفاده میشود. برای مثال، در پزشکی، مدلهای دیپ لرنینگ میتوانند تصاویر MRI و CT را تحلیل کرده و بیماریهایی مانند سرطان را با دقت بالا تشخیص دهند.
10. صدا و گفتار
دیپ لرنینگ در تحلیل صدا و گفتار نیز کاربرد دارد. این فناوری در سیستمهای تبدیل گفتار به متن (Speech-to-Text) و متن به گفتار (Text-to-Speech) استفاده میشود. برای مثال، ابزارهایی مانند Google Speech Recognition از دیپ لرنینگ برای تبدیل گفتار کاربران به متن استفاده میکنند. همچنین، این فناوری در تولید صداهای طبیعی برای دستیارهای مجازی و رباتها کاربرد دارد.
11. پزشکی و بهداشت
در حوزه پزشکی و بهداشت، دیپ لرنینگ برای تشخیص بیماریها، تحلیل تصاویر پزشکی و پیشبینی نتایج درمان استفاده میشود. برای مثال، مدلهای دیپ لرنینگ میتوانند تصاویر رادیولوژی را تحلیل کرده و بیماریهایی مانند سرطان ریه یا تومورهای مغزی را شناسایی کنند. همچنین، این فناوری در توسعه داروهای جدید و پیشبینی واکنش بیماران به درمانها کاربرد دارد.
12. بازاریابی و تجارت الکترونیک
در بازاریابی و تجارت الکترونیک، دیپ لرنینگ برای تحلیل رفتار مشتریان، پیشنهاد محصولات و بهینهسازی تبلیغات استفاده میشود. برای مثال، سیستمهای توصیهگر (Recommendation Systems) مانند آنچه در Amazon و Netflix استفاده میشود، از دیپ لرنینگ برای ارائه پیشنهادات شخصیسازیشده به کاربران بهره میبرند.
13. بازیهای ویدئویی

در بازیهای ویدئویی، دیپ لرنینگ برای ایجاد هوش مصنوعی پیشرفته استفاده میشود. این فناوری به بازیها امکان میدهد که رفتارهای طبیعیتر و چالشبرانگیزتری ارائه دهند. همچنین، دیپ لرنینگ در توسعه بازیهای تعاملی و واقعیت مجازی نیز نقش مهمی ایفا میکند.
یادگیری عمیق چگونه کار میکند؟
دیپ لرنینگ با بهره گیری از شبکههای عصبی عمیق (Deep Neural Networks)، دادهها را به صورت مرحله به مرحله در لایههای مختلف پردازش میکند. هر شبکه عصبی از چندین لایه تشکیل شده است که شامل لایه ورودی، لایههای پنهان و لایه خروجی میشود. لایههای پنهان وظیفه شناسایی و استخراج ویژگیهای خاص از دادهها را بر عهده دارند. در این فرآیند، هر لایه اطلاعات را از لایه قبلی دریافت کرده، آن را پردازش میکند و نتایج را به لایه بعدی منتقل میکند. این انتقال مرحله به مرحله به مدل اجازه میدهد تا از ویژگیهای ساده در لایههای ابتدایی به الگوهای پیچیده تر در لایههای عمیق تر برسد.
به عنوان مثال، در یک شبکه عصبی برای پردازش تصویر، لایههای اولیه ممکن است ویژگیهایی مانند لبهها یا گوشههای تصویر را شناسایی کنند، در حالی که لایههای عمیقتر به شناسایی اشیاء پیچیدهتر مانند چهرهها یا اشیاء خاص میپردازند. این فرآیند یادگیری سلسلهمراتبی باعث میشود که دیپ لرنینگ توانایی تحلیل دادههای پیچیده و غیرساختار یافته را داشته باشد. در نهایت، لایه خروجی نتایج پردازش را به شکل خروجی نهایی ارائه میدهد، مانند پیشبینی یک طبقهبندی یا تولید یک مقدار عددی. این قدرت پردازش چندلایهای، عامل اصلی موفقیت دیپ لرنینگ در مسائل پیچیده است.
از ماشین لرنینگ تا دیپ لرنینگ
در دنیای امروز، مفاهیمی مانند هوش مصنوعی (AI)، ماشین لرنینگ (Machine Learning) و دیپ لرنینگ (Deep Learning) به طور گستردهای مورد بحث قرار میگیرند. این سه مفهوم به هم مرتبط هستند اما تفاوتهای مهمی نیز دارند. ماشین لرنینگ به عنوان یکی از زیرشاخههای هوش مصنوعی، و دیپ لرنینگ به عنوان زیرمجموعهای از ماشین لرنینگ، هرکدام نقش خاصی در پیشرفت فناوری دارند. در این مقاله، به بررسی این مفاهیم و تفاوتهای آنها میپردازیم.

ماشین لرنینگ چیست؟
ماشین لرنینگ یا یادگیری ماشین، یکی از زیرشاخههای هوش مصنوعی است که به سیستمها امکان میدهد بدون نیاز به برنامهریزی صریح، از دادهها یاد بگیرند و پیشبینی کنند. در این روش، الگوریتمها با استفاده از دادههای ورودی، الگوها را شناسایی کرده و از آنها برای پیش بینی یا تصمیم گیری استفاده میکنند. به عبارت دیگر، ماشین لرنینگ به سیستمها این توانایی را میدهد که از تجربههای گذشته خود یاد بگیرند و عملکرد خود را بهبود بخشند.
برای مثال، در یک سیستم تشخیص اسپم، الگوریتمهای ماشین لرنینگ با تحلیل ایمیلهای قبلی و شناسایی الگوهای مرتبط با اسپم، میتوانند ایمیلهای جدید را به عنوان اسپم یا غیر اسپم دستهبندی کنند. این فرآیند به صورت خودکار انجام میشود و نیازی به تعریف قوانین دستی ندارد.
تفاوت ماشین لرنینگ و دیپ لرنینگ چیست؟
دیپ لرنینگ زیرمجموعهای از ماشین لرنینگ است که از شبکههای عصبی عمیق برای پردازش دادهها استفاده میکند. در حالی که ماشین لرنینگ معمولاً به الگوریتمهایی مانند رگرسیون خطی، درختهای تصمیم گیری و ماشینهای بردار پشتیبان (SVM) متکی است، دیپ لرنینگ از ساختارهای پیچیدهتری مانند شبکههای عصبی مصنوعی بهره میبرد. این شبکهها از لایههای متعددی تشکیل شدهاند که هر لایه ویژگیهای خاصی از دادهها را استخراج میکند و به لایه بعدی منتقل میکند.
تفاوت اصلی میان این دو در توانایی پردازش دادههای پیچیده و غیرساختار یافته است. ماشین لرنینگ معمولاً نیاز به استخراج ویژگیهای دستی دارد، در حالی که دیپ لرنینگ این ویژگیها را به صورت خودکار از دادهها استخراج میکند. به همین دلیل، دیپ لرنینگ در مسائل پیچیدهای مانند پردازش تصویر، پردازش زبان طبیعی و تشخیص صدا عملکرد بهتری دارد.
هوش مصنوعی و دیپ لرنینگ
هوش مصنوعی (AI) یک مفهوم کلی است که شامل تمام روشها و تکنیکهایی میشود که به ماشینها امکان میدهد رفتارهای هوشمندانهای از خود نشان دهند. ماشین لرنینگ و دیپ لرنینگ هر دو زیرمجموعههایی از هوش مصنوعی هستند. ماشین لرنینگ به سیستمها امکان میدهد که از دادهها یاد بگیرند، در حالی که دیپ لرنینگ با استفاده از شبکههای عصبی عمیق، توانایی پردازش دادههای پیچیده تر را فراهم میکند.

به عبارت دیگر، هوش مصنوعی یک چتر بزرگ است که شامل روشهای مختلفی برای شبیه سازی هوش انسانی میشود. ماشین لرنینگ یکی از این روشهاست که بر یادگیری از دادهها تمرکز دارد، و دیپ لرنینگ یکی از پیشرفتهترین ابزارهای ماشین لرنینگ است که با استفاده از ساختارهای عمیق تر، توانایی حل مسائل پیچیده تر را دارد.
الگوریتمهای محبوب دیپ لرنینگ چیست؟
دیپ لرنینگ از الگوریتمها و معماریهای مختلفی تشکیل شده است که هرکدام برای حل مسائل خاص طراحی شدهاند. این الگوریتمها با استفاده از ساختارهای پیچیده شبکههای عصبی، قادر به پردازش و تحلیل دادههای گوناگون هستند. در این میان، سه معماری اصلی و محبوب شامل شبکههای عصبی پیچشی (CNN)، شبکههای عصبی بازگشتی (RNN) و شبکههای حافظه کوتاهمدت بلند (LSTM) هستند. هر یک از این الگوریتمها در حوزههای خاصی از پردازش دادهها کاربرد دارند و توانایی حل مسائل پیچیده را بهبود میبخشند. در ادامه، این الگوریتمها و کاربردهای آنها به تفصیل بررسی میشوند.
شبکههای عصبی پیچشی (Convolutional Neural Networks - CNN)
شبکههای عصبی پیچشی یا CNN یکی از محبوب ترین الگوریتمهای دیپ لرنینگ هستند که به طور خاص برای پردازش تصاویر و دادههای بصری طراحی شدهاند. این شبکهها از لایههای پیچشی (Convolutional Layers) برای استخراج ویژگیهای محلی از تصاویر استفاده میکنند. به جای پردازش کل تصویر به صورت یکجا، CNNها با استفاده از فیلترها یا کرنلها، بخشهای کوچکی از تصویر را بررسی کرده و ویژگیهای مهمی مانند لبهها، بافتها و اشکال را شناسایی میکنند.
کاربردهای اصلی CNN شامل موارد زیر است:
- تشخیص تصویر: شناسایی اشیاء یا افراد در تصاویر (مانند تشخیص چهره).
- بینایی کامپیوتر: تحلیل تصاویر و ویدئوها در خودروهای خودران.
- پزشکی: تحلیل تصاویر پزشکی مانند اسکنهای MRI یا CT برای تشخیص بیماریها.
به عنوان مثال، معماریهای معروفی مانند AlexNet، VGG، ResNet و Inception از CNNها برای حل مسائل پیچیده در زمینه پردازش تصویر استفاده میکنند.
شبکههای عصبی بازگشتی (Recurrent Neural Networks - RNN)
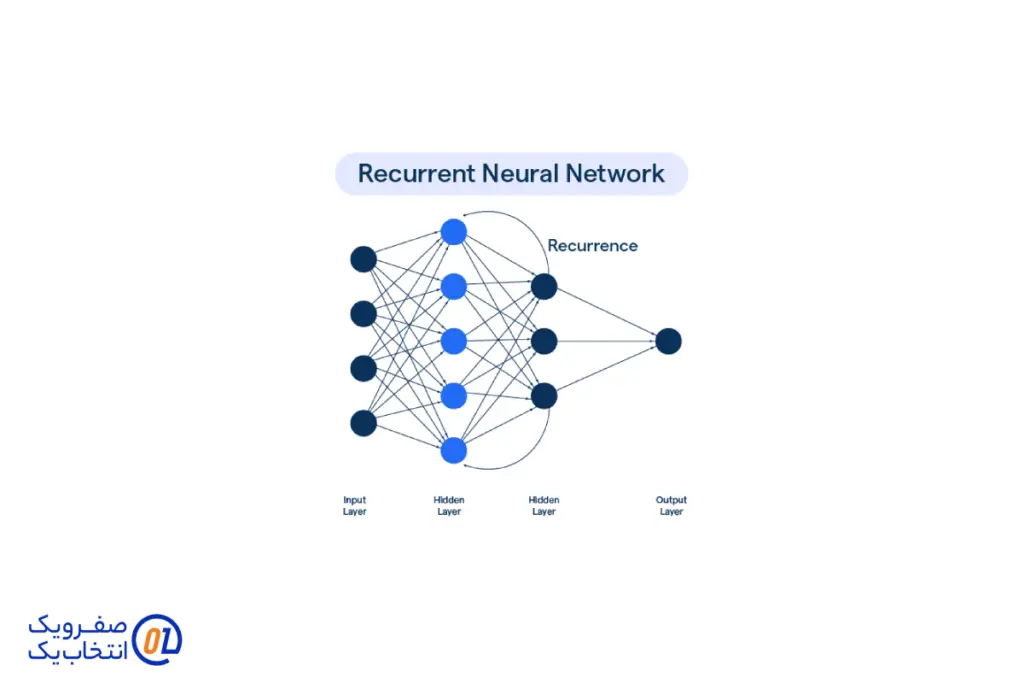
شبکههای عصبی بازگشتی یا RNN برای پردازش دادههای ترتیبی و زمانی طراحی شدهاند. برخلاف شبکههای عصبی معمولی که ورودیها را به صورت مستقل پردازش میکنند، RNNها از خروجیهای قبلی خود برای پردازش ورودیهای جدید استفاده میکنند. این ویژگی به RNNها امکان میدهد که وابستگیها و روابط طولانیمدت در دادههای ترتیبی را شناسایی کنند.
کاربردهای اصلی RNN شامل موارد زیر است:
- پردازش زبان طبیعی (NLP): تحلیل متن، ترجمه زبان و تولید متن.
- تحلیل صوت: تشخیص گفتار و تبدیل گفتار به متن.
- پیش بینی سریهای زمانی: پیشبینی قیمت سهام، آبوهوا و سایر دادههای زمانی.
با این حال، RNNها در یادگیری روابط طولانیمدت در دادهها دچار مشکل میشوند که این مسئله به نام "فراموشی گرادیان" یا Vanishing Gradient Problem شناخته میشود. برای حل این مشکل، معماریهای پیشرفتهتری مانند LSTM و GRU معرفی شدهاند.
شبکههای حافظه کوتاه مدت بلند (Long Short-Term Memory - LSTM)
LSTM یکی از پیشرفتهترین انواع RNNها است که برای رفع مشکل فراموشی گرادیان طراحی شده است. این شبکهها با اضافه کردن یک ساختار داخلی به نام "سلول حافظه"، به مدل امکان میدهند که اطلاعات مهم را برای مدت طولانیتری ذخیره کرده و اطلاعات غیرضروری را فراموش کنند. این ویژگی، LSTM را به ابزاری قدرتمند برای تحلیل دادههای ترتیبی و زمانی تبدیل کرده است.
کاربردهای اصلی LSTM شامل موارد زیر است:
- پیشبینی سریهای زمانی: مانند پیشبینی تغییرات آب و هوا یا روند بازارهای مالی.
- تولید متن و موسیقی: تولید متون طبیعی یا قطعات موسیقی بر اساس دادههای قبلی.
- ترجمه زبان: استفاده در مدلهایی مانند Google Translate برای ترجمه جملات.
LSTMها به دلیل توانایی در یادگیری روابط طولانی مدت، در مسائل پیچیدهای که نیاز به تحلیل وابستگیهای طولانیمدت دارند، عملکرد بسیار بهتری نسبت به RNNهای ساده ارائه میدهند.
| الگوریتم | مناسب برای |
| CNN | دادههای بصری مانند تصاویر و ویدئوها. |
| RNN | دادههای ترتیبی و وابسته به زمان مانند متن و صدا. |
| LSTM | مسائل پیچیدهتر که نیاز به حفظ اطلاعات بلندمدت در دادههای ترتیبی و زمانی دارند. |
بهترین ابزارها و فریم ورکها برای یادگیری عمیق

یادگیری عمیق به دلیل پیچیدگی محاسباتی نیازمند ابزارها و فریم ورکهایی است که توسعه و آموزش مدلها را ساده تر کنند. امروزه، فریم ورکهای متعددی برای این منظور وجود دارند که هرکدام ویژگیها و کاربردهای خاص خود را دارند. در ادامه، به معرفی برخی از بهترین ابزارها و فریم ورکهای یادگیری عمیق میپردازیم:
- TensorFlow: یکی از قدرتمندترین و محبوبترین فریم ورکهای یادگیری عمیق که توسط Google توسعه یافته و قابلیتهای گستردهای برای ساخت و آموزش مدلهای پیچیده فراهم میکند.
- Keras: یک API سطح بالا که بر روی TensorFlow اجرا میشود و محیطی ساده و کاربر پسند برای طراحی مدلها ارائه میدهد.
- PyTorch: فریم ورکی انعطاف پذیر و کارآمد که توسط Facebook توسعه داده شده و به دلیل سادگی و پشتیبانی از محاسبات پویا، محبوبیت زیادی دارد.
- MXNet: فریم ورکی سریع و مقیاسپذیر که به ویژه در پردازش دادههای بزرگ و موازی سازی کاربرد دارد.
- Caffe: ابزاری سبک و سریع برای آموزش مدلهای یادگیری عمیق، به ویژه در پردازش تصویر.
- Theano: یکی از اولین فریم ورکهای یادگیری عمیق که امکان انجام محاسبات پیچیده ریاضی را فراهم میکند.
- JAX: فریم ورکی مدرن و قدرتمند که توسط Google توسعه یافته و برای محاسبات عددی و یادگیری ماشین استفاده میشود.
- Fastai: کتابخانهای ساده و کارآمد که بر اساس PyTorch ساخته شده و برای آموزش سریع مدلها طراحی شده است.
- ONNX: ابزاری برای تبادل مدلهای یادگیری عمیق میان فریمورکهای مختلف.
- Chainer: فریم ورکی منعطف برای یادگیری عمیق که محاسبات پویا را به خوبی پشتیبانی میکند.
این ابزارها بر اساس نیاز پروژه و سطح تجربه کاربر انتخاب میشوند و هرکدام در حوزههای خاصی عملکرد بهینهای دارند.
چالشها و محدودیتهای یادگیری عمیق
یادگیری عمیق (Deep Learning) به عنوان یکی از پیشرفتهترین شاخههای هوش مصنوعی، توانسته است در بسیاری از حوزهها انقلابی ایجاد کند. با این حال، این فناوری با چالشها و محدودیتهایی نیز همراه است که میتواند مانع از استفاده گستردهتر آن شود. در ادامه، به بررسی مهمترین چالشها و محدودیتهای یادگیری عمیق میپردازیم:
1. نیاز به دادههای بزرگ و باکیفیت
یکی از بزرگترین چالشهای یادگیری عمیق، نیاز به حجم زیادی از دادههای باکیفیت برای آموزش مدلها است. مدلهای دیپ لرنینگ برای یادگیری الگوهای پیچیده به دادههای متنوع و گسترده نیاز دارند. اگر دادهها ناکافی یا دارای نویز باشند، عملکرد مدل به شدت کاهش مییابد. جمعآوری و برچسبگذاری این دادهها نیز زمانبر و پرهزینه است. به عنوان مثال، در حوزه پزشکی، جمعآوری تصاویر پزشکی باکیفیت و برچسبگذاری دقیق آنها توسط متخصصان، یکی از چالشهای اصلی است.
2. مصرف بالای منابع محاسباتی
مدلهای یادگیری عمیق به دلیل ساختار پیچیده خود، نیازمند منابع محاسباتی قدرتمند هستند. آموزش این مدلها به سختافزارهایی مانند پردازندههای گرافیکی (GPU) یا واحدهای پردازش تنسور (TPU) نیاز دارد که هزینه بالایی دارند. علاوه بر این، مصرف انرژی این سختافزارها نیز بسیار زیاد است و میتواند از نظر زیستمحیطی چالشبرانگیز باشد. این محدودیت باعث میشود که استفاده از یادگیری عمیق برای بسیاری از سازمانها و افراد دشوار باشد.
3. پیچیدگی در تنظیم و بهینهسازی مدلها
تنظیم و بهینهسازی مدلهای دیپ لرنینگ فرآیندی پیچیده و زمانبر است. انتخاب معماری مناسب، تنظیم هایپرپارامترها (مانند نرخ یادگیری، تعداد لایهها و نورونها) و جلوگیری از مشکلاتی مانند بیشبرازش (Overfitting) نیازمند دانش تخصصی و تجربه است. علاوه بر این، فرآیند آزمایش و خطا برای یافتن بهترین تنظیمات میتواند بسیار طولانی باشد.
4. تفسیرپذیری پایین
یکی از محدودیتهای اصلی یادگیری عمیق، تفسیرپذیری پایین مدلها است. مدلهای دیپ لرنینگ به عنوان "جعبه سیاه" شناخته میشوند، زیرا درک نحوه تصمیمگیری آنها دشوار است. این مسئله به ویژه در حوزههایی مانند پزشکی یا حقوق که شفافیت تصمیمگیری اهمیت زیادی دارد، چالشبرانگیز است. برای مثال، اگر یک مدل دیپ لرنینگ تشخیص دهد که یک بیمار به بیماری خاصی مبتلا است، توضیح دلیل این تشخیص برای پزشکان و بیماران ممکن است دشوار باشد.
دورنما و آینده یادگیری عمیق
با وجود چالشها، یادگیری عمیق همچنان در حال پیشرفت است و آیندهای روشن دارد. پیشرفتهای مداوم در سختافزار (مانند پردازندههای سریعتر و کممصرفتر) و الگوریتمها (مانند مدلهای کارآمدتر و تفسیرپذیرتر) میتواند بسیاری از این محدودیتها را کاهش دهد. در آینده، یادگیری عمیق نقش بیشتری در زندگی روزمره ما ایفا خواهد کرد. از پزشکی (مانند تشخیص بیماریها و توسعه داروهای جدید) و حملونقل (مانند خودروهای خودران) گرفته تا آموزش (مانند سیستمهای یادگیری شخصیسازیشده) و سرگرمی (مانند بازیهای ویدئویی و تولید محتوای خلاقانه)، دیپ لرنینگ به یکی از ابزارهای کلیدی در حل مسائل پیچیده تبدیل خواهد شد.
دنیای صفر و یک
با خدمات اینترنتی صفر و یک، شما میتوانید به راحتی کامپیوتر خود را به وای فای متصل کنید و از سرعت و کیفیت بینظیر اینترنت لذت ببرید!
برای همکاری و اطلاع از تعرفه ها تماس بگیرید.